
LLM常用任务类型
这篇文章是LLM环境搭建完成后,基于HuggingFace,马上可以开始尝试的一些事情
基本上,就是通过调用模型完成一些简单的任务(分词与编码/情感分析/翻译/文本生成/本地问答),简单的熟悉一下这些东西:
工作流程
模型使用基本思路
模型的id2label大概原理
模型的两种加载方式大概了解
模型的简单优化策略
模型的简单微调训练
分词与编码
想做什么?
提取中文文本中的token序列及其编号
任务类型?
huggingface没有直接的任务分类对应『token提取及编号获取』
所以需要分析任务的子集、超集、同类任务有没有对应分类
token提取已经是基本任务,所以向上查找父级任务,也就是文本分析处理(Text Classification/Token Classification) + 中文支持
考虑到我是需要处理token,所以最终在Token Classification任务类型中找支持中文的模型
哪个模型?
FacebookAI/xlm-roberta-large-finetuned-conll03-english
虽然说是english,但它支持94种语言,包括中文
如何初始化?
官方文档如此描述:
# Load model directly
from transformers import AutoTokenizer, AutoModelForTokenClassification
tokenizer = AutoTokenizer.from_pretrained("FacebookAI/xlm-roberta-large-finetuned-conll03-english")
model = AutoModelForTokenClassification.from_pretrained("FacebookAI/xlm-roberta-large-finetuned-conll03-english")我需要的是处理token,获取其编号,所以只要创建一个tokenizer就行了
python语言的特性,tokenizer没有静态类型,idea无法提示其中的方法
print(f"type: {type(tokenizer)}")结果如下:
type: <class 'transformers.models.xlm_roberta.tokenization_xlm_roberta_fast.XLMRobertaTokenizerFast'>依据XLMRobertaTokenizerFast的api定义,即可得知获取token(tokenize)及编号(convert_tokens_to_ids)的方法
总结如下
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("FacebookAI/xlm-roberta-large-finetuned-conll03-english")
tokens = tokenizer.tokenize("刻晴是璃月七星之玉衡,她负表管理璃月的土地与建设")
token_ids = tokenizer.convert_tokens_to_ids(tokens)
print("tokens:")
for (token, id) in list(zip(tokens, token_ids)):
print(f"'{token}': {id}")结果如下:
'▁': 6
'刻': 30815
'晴': 69225
'是': 354
'璃': 243970
'月': 630
'七': 12245
'星': 7367
'之': 1420
'玉': 20182
'衡': 147229
',': 4
'她': 1685
'负': 37220
'表': 5873
'管理': 2438
'璃': 243970
'月': 630
'的': 43
'土地': 20770
'与': 1189
'建设': 5722情感分析
想做什么?
给定一句中文,获取其中的感情倾向
任务类型?
huggingface的任务分类中没有直接的『emotion』之类的选项
但情感分析相较token提取属于比较不那么底层的任务,可以试试直接搜索『emotion』
哪个模型?
Johnson8187/Chinese-Emotion
如何初始化?
模型官方有quick-start,参照写出如下逻辑:
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
emotion_mapping = {
0: "平淡",
1: "关切",
2: "开心",
3: "愤怒",
4: "悲伤",
5: "疑问",
6: "惊奇",
7: "厌恶",
}
device = torch.device("cuda")
tokenizer = AutoTokenizer.from_pretrained("Johnson8187/Chinese-Emotion")
model = AutoModelForSequenceClassification.from_pretrained("Johnson8187/Chinese-Emotion").to(device)
inputs = tokenizer("好奇怪!", return_tensors="pt", truncation=True, padding=True).to(device)
with torch.no_grad():
outputs = model(**inputs)
predicted_class = torch.argmax(outputs.logits).item()
print(emotion_mapping[predicted_class])输出结果如下:
惊奇效果不错,但我觉得太麻烦,参照Hugging Face的Pipelines教程,写出如下逻辑:
from transformers import pipeline
pipe = pipeline("text-classification", model="Johnson8187/Chinese-Emotion")
print(pipe("好奇怪!"))输出结果如下:
[{'label': 'LABEL_6', 'score': 0.9833084344863892}]猜测是id2label的问题,再次尝试:
from transformers import pipeline
pipe = pipeline("text-classification", model="Johnson8187/Chinese-Emotion")
print(pipe("好奇怪!"))
print(pipe("太奇怪了!"))
print(pipe("我很开心!"))
print(pipe("超级开心!"))结果如下:
[{'label': 'LABEL_6', 'score': 0.9833084344863892}]
[{'label': 'LABEL_6', 'score': 0.980847954750061}]
[{'label': 'LABEL_2', 'score': 0.990023672580719}]
[{'label': 'LABEL_2', 'score': 0.9889615178108215}]出现了『符合输入语义&结构一致的&分布可重复』的结果,证明是id2label未配置,验证:
from transformers import pipeline
pipe = pipeline("text-classification", model="Johnson8187/Chinese-Emotion")
print(pipe.model.config.id2label)结果如下:
{0: 'LABEL_0', 1: 'LABEL_1', 2: 'LABEL_2', 3: 'LABEL_3', 4: 'LABEL_4', 5: 'LABEL_5', 6: 'LABEL_6', 7: 'LABEL_7'}这说明结果确实是正确的,只是没有映射到人类可读文本,结合模型官方的quick-start,写出如下逻辑:
from transformers import pipeline
pipe = pipeline("text-classification", model="Johnson8187/Chinese-Emotion")
pipe.model.config.id2label = {
0: "平淡",
1: "关切",
2: "开心",
3: "愤怒",
4: "悲伤",
5: "疑问",
6: "惊奇",
7: "厌恶",
}
print(pipe("好奇怪!"))
print(pipe("太奇怪了!"))
print(pipe("我很开心!"))
print(pipe("超级开心!"))结果如下:
[{'label': '惊奇', 'score': 0.9833084344863892}]
[{'label': '惊奇', 'score': 0.980847954750061}]
[{'label': '开心', 'score': 0.990023672580719}]
[{'label': '开心', 'score': 0.9889615178108215}]完美,不仅简单,还有置信度
但是我觉得还不够,为什么是『0-7』?我想看到更多的一些东西
所以,需要绕过pipeline的封装,直接获取模型的原始输出,查看它的输出是什么内容
依据官方的quick-start可知,使用argmax处理logits即可获取概率最高的结果的索引
logits是什么?
模型会输出一个浮点数数组,其元素为模型选择元素索引对应的结果的偏向度
元素值越大,说明模型越倾向于元素索引对应的结果
logits长度,就是模型可输出的结果种类数
从id2label来看,这个模型的logits应该是一个一维数组,有八个元素,代表这个模型的输出有八种可能,所以是0-7
argmax做了什么?
从输入中获取最大值的索引,就是一个简单的index(max(input))
针对logits使用argmax,就可以得出模型在它给出的X种可能中,最偏向哪种
但是存在一种情况,模型同时偏向于多种结果,说明模型不确定当前输入属于哪一类,此时预测具有高不确定性
而因为logits偏向度是一个浮点数组,判断『有几个元素大致相等』不再是一件很简单的事情,这一结论的得出变得困难
此时,需要某种操作,把logits转换成概率,进而计算熵值
softmax,就是那个把原始偏向度转换成概率的方法
它会将任意实数向量转换为概率分布,所有值都为0~1,放大大的值,缩小小的值,使得模型最偏向的索引进一步突出,且总和为1,这个操作就叫『归一化』
softmax输出的概率分布同样是一个数组,每个元素为模型得出的该元素索引对应的结果的置信度
此时,可以通过熵计算得知『模型是否得出了有效结果』:
熵值越大,说明模型越没有把握
熵值越小,说明模型越有信心
不过对于官方的quick-start,它只是需要知道模型最偏向于哪一结果,所以无需使用softmax,直接avgmax获取模型最偏向的结果就好
那么,统合以上,写成如下逻辑:
def predicate(text: str):
inputs = tokenizer(text, return_tensors="pt").to(device)
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
print("logits: ", logits[0].tolist())
probs = torch.softmax(logits, dim=-1)
print("probs: ", probs[0].tolist())
argmax = torch.argmax(logits, dim=-1)
print("argmax: ", argmax)
pred_id = argmax.item()
score = probs[0, pred_id]
print("score: ", score)
pred_score = score.item()
id2label = {
0: "中性", 1: "愤怒", 2: "喜悦", 3: "伤心",
4: "厌恶", 5: "恐惧", 6: "惊讶", 7: "疑惑"
}
print(f"预测标签: {id2label[pred_id]},置信度: {pred_score:.4f}")针对好奇怪!,输出如下:
input: 好奇怪!
logits: [-0.6327104568481445, -1.1725515127182007, 1.210888385772705, -0.35720375180244446, -1.8332749605178833, -0.8756855726242065, 5.806886672973633, -1.7587075233459473]
probs: [0.001570392632856965, 0.0009152889833785594, 0.00992368720471859, 0.0020685174968093634, 0.0004727263003587723, 0.00123164476826787, 0.9833084344863892, 0.0005093237850815058]
argmax: tensor([6], device='cuda:0')
score: tensor(0.9833, device='cuda:0')
预测标签: 惊讶,置信度: 0.9833从如下角度分析:
logits是一个浮点数组,它代表模型这次运行输出了8个结果,而索引6的元素值最大,表示模型最偏向于索引6的结果
probs是softmax归一之后的结果,它将logits转换成了一个『所有元素之和为1』的数组,且保持了每个元素之间的大小对应关系,索引6同样为最大元素,表明索引6的置信度最高,索引6则为这次运行的结果
argmax就是取出了索引值6
如果模型未提供
id2label,且文档没有给出id2label的情况下,可以通过多个典型输入反复实验(如“愤怒”、“开心”、“悲伤”等)推断每个索引对应的情绪标签,从而构造出id2label字典
翻译
想做什么?
中 -> 英
任务类型?
translation
哪个模型?
Helsinki-NLP/opus-mt-zh-en
明明有Facebook的模型,为什么选它?
因为它提供了直接预览的接口,我喜欢这个功能
如何初始化?
参照模型官方文档,写出如下逻辑:
from transformers import pipeline
pipe = pipeline("translation", model="Helsinki-NLP/opus-mt-zh-en")
print(pipe("这是一个比较长的,结构比较复杂的,加了标点符号的句子"))出现了报错:
ValueError: Due to a serious vulnerability issue in `torch.load`, even with `weights_only=True`, we now require users to upgrade torch to at least v2.6 in order to use the function. This version restriction does not apply when loading files with safetensors.
See the vulnerability report here https://nvd.nist.gov/vuln/detail/CVE-2025-32434(nlp-journey) fallingangel@FallingAngel:~/nlp-journey$ pip list | grep torch
torch 2.5.1+cu121
torchaudio 2.5.1+cu121
torchvision 0.20.1+cu121查看本地torch版本发现确实不够,按照提示信息中的提示查看模型加载方法,发现可以使用safetensors加载模型文件:
from transformers import pipeline, AutoTokenizer, AutoModelForSeq2SeqLM
model = AutoModelForSeq2SeqLM.from_pretrained("Helsinki-NLP/opus-mt-zh-en", use_safetensors=True)
tokenizer = AutoTokenizer.from_pretrained("Helsinki-NLP/opus-mt-zh-en")
pipe = pipeline("translation_zh_to_en", model=model, tokenizer=tokenizer)
print(pipe("这是一个比较长的,结构比较复杂的,加了标点符号的句子"))结果如下:
[{'translation_text': "It's a long, complicated sentence with a punctuation."}]文本生成
想做什么?
给出提示词,生成kotlin快速排序代码
任务类型?
text-generation
这是纯粹的文本生成,不需要text2text-generation
哪个模型?
JetBrains/Mellum-4b-sft-kotlin
如何初始化?
参照模型官方文档,写出如下逻辑:
from transformers import pipeline
pipe = pipeline("text-generation", model="JetBrains/Mellum-4b-sft-kotlin")
print(pipe("实现一个快速排序方法")[0]["generated_text"])结果如下:
import *
import
import org.junit.Assert.assertEquals
fun assertEquals(expected: Double, actual: Double, epsilon: Double) {
assertEquals("$expected (epsilon=$epsilon)", expected, actual, Math.pow(10.0, -epsilon))
}
fun assertEquals(expected: Int, actual: Int) {
assertEquals("$expected", expected, actual)
}但这是个4b参数的模型,就这么直接调用性能需求特别高特别卡特别慢,而且生成的东西大概率有错误,所以我需要采取一些优化措施
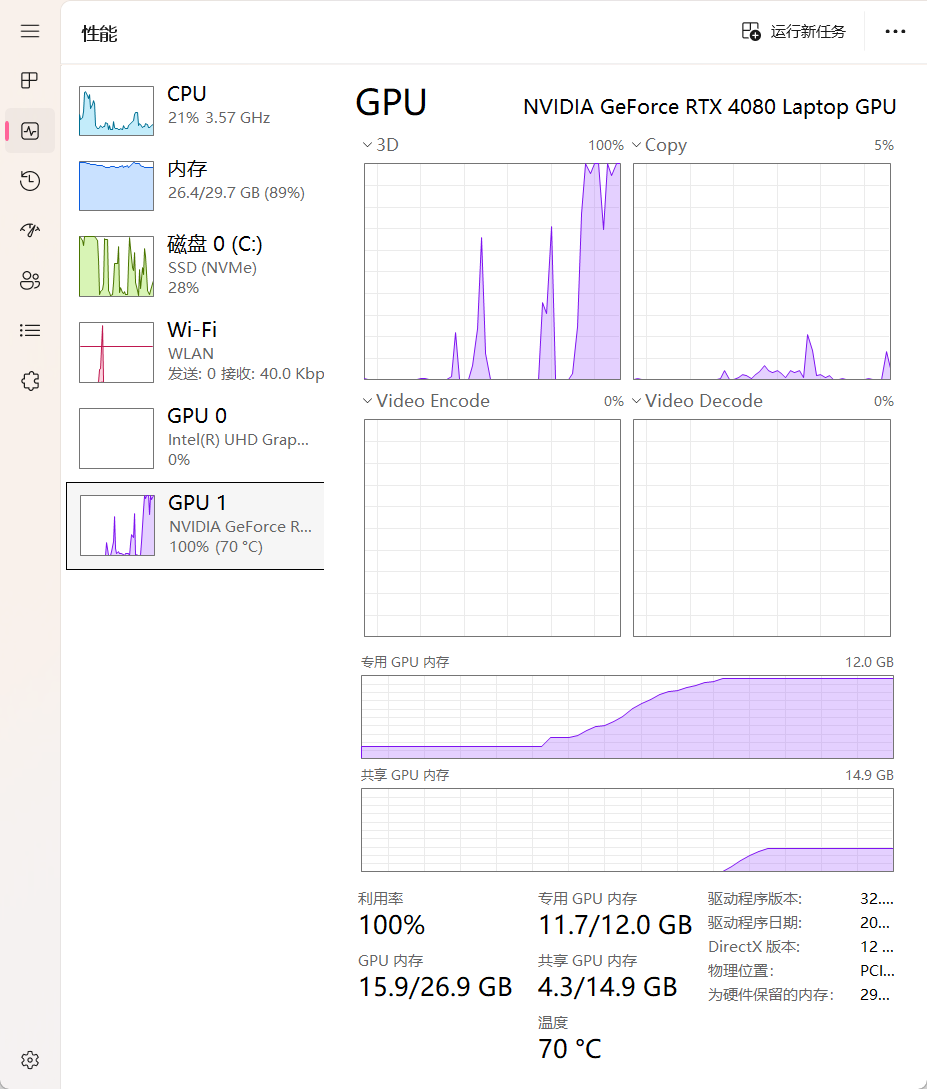
模型的优化通常有四个级别,32、16、8、4,默认是32,我先降到16;同时,这是个SFT模型,提示词需要调整:
import torch
from transformers import pipeline
prompt = """请用 Kotlin 编写一个快速排序函数:
```kotlin
"""
pipe = pipeline("text-generation", model="JetBrains/Mellum-4b-sft-kotlin", torch_dtype=torch.float16)
print(pipe(prompt)[0]["generated_text"])生成结果如下:
fun quickSort(nums: IntArray) {
val list = mutableListOf<Int>()
for (num in nums) {
list.add(num)
}
quickSort(list)
}
fun quickSort(list: MutableList<Int>) {
if (list.size <= 1) {
return
}
val pivot = list[list.size / 2]
val newList = mutableListOf<Int>()
for (num in list) {
if (num <= pivot) {
newList.add(num)
} else {模型输出长度不够,被截断了。pipe应该有相关参数,但其类型不知道是什么(我讨厌python),使用rich打印其参数列表:
import torch
from transformers import pipeline
from rich import inspect
prompt = """请用 Kotlin 编写一个快速排序函数:
```kotlin
"""
pipe = pipeline("text-generation", model="JetBrains/Mellum-4b-sft-kotlin", torch_dtype=torch.float16)
inspect(pipe)╭─ <transformers.pipelines.text_generation.TextGenerationPipeline object at 0x─╮
│ def (text_inputs, **kwargs): │
│ │
│ Language generation pipeline using any `ModelWithLMHead` or │
│ `ModelForCausalLM`. This pipeline predicts the words │
│ that will follow a specified text prompt. When the underlying model is a │
│ conversational model, it can also accept │
│ one or more chats, in which case the pipeline will operate in chat mode and │
│ will continue the chat(s) by adding │
│ its response(s). Each chat takes the form of a list of dicts, where each │
│ dict contains "role" and "content" keys. │
│ │
│ assistant_model = None │
│ assistant_tokenizer = None │
│ binary_output = False │
│ call_count = 0 │
│ default_input_names = None │
│ device = device(type='cuda', index=0) │
│ feature_extractor = None │
│ framework = 'pt' │
│ generation_config = GenerationConfig { │
│ "bos_token_id": 0, │
│ "do_sample": true, │
│ "eos_token_id": 0, │
│ "max_new_tokens": 256, │
│ "pad_token_id": 0, │
│ "temperature": 0.7 │
│ } │
│ image_processor = None │
│ modelcard = None │
│ prefix = None │
│ processor = None │
│ task = 'text-generation' │
│ torch_dtype = torch.float16 │
│ XL_PREFIX = "\n In 1991, the remains of Russian Tsar Nicholas │
│ II and his family (except for Alexei and Maria) are │
│ discovered. The\n voice of Nicholas's young son, │
│ Tsarevich Alexei Nikolaevich, narrates the remainder │
│ of the story. 1883 Western\n Siberia, a young │
│ Grigori Rasputin is asked by his father and a group of │
│ men to perform magic. Rasputin has a vision\n and │
│ denounces one of the men as a horse thief. Although │
│ his father initially slaps him for making such an\n │
│ accusation, Rasputin watches as the man is chased │
│ outside and beaten. Twenty years later, Rasputin sees │
│ a vision of\n the Virgin Mary, prompting him to │
│ become a priest. Rasputin quickly becomes famous, with │
│ people, even a bishop,\n begging for his blessing. │
│ <eod> </s> <eos>\n " │
╰──────────────────────────────────────────────────────────────────────────────╯结合参数信息,调整pipe调用方式:
import torch
from transformers import pipeline, GenerationConfig
prompt = """// 请用 Kotlin 实现快速排序(Quick Sort),含注释
fun quickSort(arr: MutableList<Int>): MutableList<Int> {
"""
pipe = pipeline("text-generation", model="JetBrains/Mellum-4b-sft-kotlin", torch_dtype=torch.float16)
print(pipe(prompt, generation_config=GenerationConfig(max_new_tokens=1000))[0]["generated_text"])结果如下:
// 请用 Kotlin 实现快速排序(Quick Sort),含注释
fun quickSort(arr: MutableList<Int>): MutableList<Int> {
// 递归结束条件
fun isSorted(arr: MutableList<Int>): Boolean {
// 递归结束条件
if (arr.size <= 1) {
return true
}
// 逻辑处理 进入下层循环
// 取最后一个元素作为 pivot
val last = arr[arr.size - 1]
var i = 0
for (j in 0 until arr.size - 1) {
// 如果当前元素比 pivot 大
if (arr[j] > last) {
// 交换位置
val temp = arr[j]
arr[j] = arr[i]
arr[i] = temp
i++
}
}
// 递归返回结果
// 因为数组是排好序的,所以第一个元素是最大的
return isSorted(arr.subList(0, arr.size - 1))
&& isSorted(arr.subList(1, arr.size))
}
// 逻辑处理 进入下层循环
quickSort(arr)
return arr
}
fun main() {
val arr = mutableListOf(9, 1, 2, 3, 4, 5, 6, 7, 8)
quickSort(arr)
println(arr)
}
// 快速排序
// 时间复杂度:O(nlogn)
// 空间复杂度:O(logn)本地问答
想做什么?
给定一些文本,向模型发起问题
任务类型?
question-answering
哪个模型?
luhua/chinese_pretrain_mrc_roberta_wwm_ext_large
如何初始化?
参照官方文档,写出如下逻辑:
from transformers import pipeline
pipe = pipeline("question-answering", model="luhua/chinese_pretrain_mrc_roberta_wwm_ext_large")...然后出现这个问题,切换到safetensors方式加载
from rich import inspect
from transformers import pipeline, AutoModelForQuestionAnswering, AutoTokenizer
model = AutoModelForQuestionAnswering.from_pretrained("luhua/chinese_pretrain_mrc_roberta_wwm_ext_large", use_safetensors=True)
tokenizer = AutoTokenizer.from_pretrained("luhua/chinese_pretrain_mrc_roberta_wwm_ext_large")
pipe = pipeline("question-answering", model=model, tokenizer=tokenizer)但是不知道pipe需要什么参数,按照之前的经验,使用rich查看pipe对象
# inspect(pipe)
╭─ <transformers.pipelines.question_answering.QuestionAnsweringPipeline object─╮
│ def (*args, **kwargs): │
│ │
│ Question Answering pipeline using any `ModelForQuestionAnswering`. See the │
│ [question answering │
│ examples](../task_summary#question-answering) for more information. │
│ │
│ binary_output = False │
│ call_count = 0 │
│ default_input_names = 'question,context' │
│ device = device(type='cuda', index=0) │
│ feature_extractor = None │
│ framework = 'pt' │
│ handle_impossible_answer = False │
│ image_processor = None │
│ modelcard = None │
│ processor = None │
│ task = 'question-answering' │
│ torch_dtype = torch.float32 │
╰──────────────────────────────────────────────────────────────────────────────╯...但是依然没有类型,quention和context应该传什么进去?
此时有两个方案,直接猜,然后看报错;使用python的__call__.__doc__查看;我选择后者:
print(pipe.__call__.__doc__)Answer the question(s) given as inputs by using the context(s).
Args:
question (`str` or `List[str]`):
One or several question(s) (must be used in conjunction with the `context` argument).
context (`str` or `List[str]`):
One or several context(s) associated with the question(s) (must be used in conjunction with the
`question` argument).
top_k (`int`, *optional*, defaults to 1):
The number of answers to return (will be chosen by order of likelihood). Note that we return less than
top_k answers if there are not enough options available within the context.
doc_stride (`int`, *optional*, defaults to 128):
If the context is too long to fit with the question for the model, it will be split in several chunks
with some overlap. This argument controls the size of that overlap.
max_answer_len (`int`, *optional*, defaults to 15):
The maximum length of predicted answers (e.g., only answers with a shorter length are considered).
max_seq_len (`int`, *optional*, defaults to 384):
The maximum length of the total sentence (context + question) in tokens of each chunk passed to the
model. The context will be split in several chunks (using `doc_stride` as overlap) if needed.
max_question_len (`int`, *optional*, defaults to 64):
The maximum length of the question after tokenization. It will be truncated if needed.
handle_impossible_answer (`bool`, *optional*, defaults to `False`):
Whether or not we accept impossible as an answer.
align_to_words (`bool`, *optional*, defaults to `True`):
Attempts to align the answer to real words. Improves quality on space separated languages. Might hurt on
non-space-separated languages (like Japanese or Chinese)
Return:
A `dict` or a list of `dict`: Each result comes as a dictionary with the following keys:
- **score** (`float`) -- The probability associated to the answer.
- **start** (`int`) -- The character start index of the answer (in the tokenized version of the input).
- **end** (`int`) -- The character end index of the answer (in the tokenized version of the input).
- **answer** (`str`) -- The answer to the question.于是可以写出如下逻辑:
from transformers import pipeline, AutoModelForQuestionAnswering, AutoTokenizer
model = AutoModelForQuestionAnswering.from_pretrained("luhua/chinese_pretrain_mrc_roberta_wwm_ext_large", use_safetensors=True)
tokenizer = AutoTokenizer.from_pretrained("luhua/chinese_pretrain_mrc_roberta_wwm_ext_large")
pipe = pipeline("question-answering", model=model, tokenizer=tokenizer)
question = ["谁今天很高兴?", "谁在冒险?", "在哪里冒险?", "谁在想空?"]
answers = pipe(question=question, context="提瓦特大陆很大,空正在冒险。刻晴今天心情很好,她想空了。")
for i, answer in enumerate(answers):
print(question[i])
print(answer, "\n")输出如下:
谁今天很高兴?
{'score': 1.7728491002344526e-05, 'start': 14, 'end': 16, 'answer': '刻晴'}
谁在冒险?
{'score': 3.959689820476342e-08, 'start': 8, 'end': 16, 'answer': '空正在冒险。刻晴'}
在哪里冒险?
{'score': 0.0011206833878532052, 'start': 0, 'end': 5, 'answer': '提瓦特大陆'}
谁在想空?
{'score': 7.589447341160849e-05, 'start': 14, 'end': 16, 'answer': '刻晴'}可以看到第二个问题的上下文理解不对,所有回答的置信度也低得几乎不可用,针对我的上下文的问题模型理解能力很低,需要精调再训练
因为我只是在『尝试做些什么』,所以不考虑泛用,不考虑实际意义,因此我的训练只针对这一个上下文和这四个问题,于是写出如下训练数据和训练逻辑:
[
{
"id": "q1",
"question": "谁今天很高兴?",
"context": "提瓦特大陆很大,空正在冒险。刻晴今天心情很好,她想空了。",
"answer": {
"text": "刻晴",
"answer_start": 14,
"answer_end": 16
}
},
{
"id": "q2",
"question": "谁在冒险?",
"context": "提瓦特大陆很大,空正在冒险。刻晴今天心情很好,她想空了。",
"answer": {
"text": "空",
"answer_start": 8,
"answer_end": 9
}
},
{
"id": "q3",
"question": "在哪里冒险?",
"context": "提瓦特大陆很大,空正在冒险。刻晴今天心情很好,她想空了。",
"answer": {
"text": "提瓦特大陆",
"answer_start": 0,
"answer_end": 5
}
},
{
"id": "q4",
"question": "谁在想空?",
"context": "提瓦特大陆很大,空正在冒险。刻晴今天心情很好,她想空了。",
"answer": {
"text": "刻晴",
"answer_start": 14,
"answer_end": 16
}
}
]from datasets import load_dataset
from transformers import AutoModelForQuestionAnswering, AutoTokenizer, TrainingArguments, Trainer
model = AutoModelForQuestionAnswering.from_pretrained("luhua/chinese_pretrain_mrc_roberta_wwm_ext_large", use_safetensors=True)
tokenizer = AutoTokenizer.from_pretrained("luhua/chinese_pretrain_mrc_roberta_wwm_ext_large")
def prepare_features(example):
tokenized = tokenizer(
example["question"],
example["context"],
truncation=True,
padding="max_length",
)
# [CLS] question tokens [SEP] context tokens [SEP]
question_tokens = tokenizer.tokenize(example["question"])
context_offset = len(question_tokens) + 2 # [CLS], [SEP]
tokenized["start_positions"] = example["answer"]["answer_start"] + context_offset
tokenized["end_positions"] = example["answer"]["answer_end"] - 1 + context_offset
return tokenized
dataset = load_dataset("json", data_files="./training_data/data.json")
dataset = dataset.map(prepare_features)
training_args = TrainingArguments(
output_dir="./model",
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset["train"],
processing_class=tokenizer,
)
trainer.train()这会在当前路径下创建一个model目录,新的模型会放在其中:
(nlp-journey) fallingangel@FallingAngel:~/nlp-journey/05_local_qa$ tree model/
model/
└── checkpoint-3
├── config.json
├── model.safetensors
├── optimizer.pt
├── rng_state.pth
├── scheduler.pt
├── special_tokens_map.json
├── tokenizer.json
├── tokenizer_config.json
├── trainer_state.json
├── training_args.bin
└── vocab.txt
2 directories, 11 files于是,就可以这样使用新模型:
from transformers import pipeline, AutoModelForQuestionAnswering, AutoTokenizer
model = AutoModelForQuestionAnswering.from_pretrained("./model/checkpoint-3", use_safetensors=True)
tokenizer = AutoTokenizer.from_pretrained("./model/checkpoint-3")
pipe = pipeline("question-answering", model=model, tokenizer=tokenizer)
question = ["谁今天很高兴?", "谁在冒险?", "在哪里冒险?", "谁在想空?"]
answers = pipe(question=question, context="提瓦特大陆很大,空正在冒险。刻晴今天心情很好,她想空了。")
for i, answer in enumerate(answers):
print(question[i])
print(answer, "\n")谁今天很高兴?
{'score': 0.9980093240737915, 'start': 14, 'end': 16, 'answer': '刻晴'}
谁在冒险?
{'score': 0.9573289155960083, 'start': 8, 'end': 9, 'answer': '空'}
在哪里冒险?
{'score': 0.987471878528595, 'start': 0, 'end': 5, 'answer': '提瓦特大陆'}
谁在想空?
{'score': 0.9947592616081238, 'start': 14, 'end': 16, 'answer': '刻晴'}结果就很不错了——但这只是一个『针对性的一对一训练』,完全的过拟合,只是体验训练过程,实际上的训练应该考虑很多东西