
LLM模型的训练
有些时候,一个模型虽然已经很好用了,但在某些场景下仍不满足需求(比如之前的这次尝试),就可以使用HuggingFace提供的api对它进行再训练,把自己的场景也包含进去
在那次尝试中,为了快速看到效果,我跳过、简化了许多关键步骤,整个过程本质上是一场“过拟合实验”,那只是一个体验——可用,但不通用
这里,基于那次尝试,正式梳理一个抽取式问答(Extractive QA)模型的完整训练过程
不同模型有不同的训练流程,但大体逻辑是一致的
模型的训练是什么?
训练不是传授规则,而是塑造行为
我们并不告诉模型什么是语法,也不会向它解释“什么叫合理的回答”。训练的本质是提供大量输入与期望输出,让模型在不断试错与反馈中逐步调整参数,使输出逼近目标
它并没有理解语言,仅仅是统计意义上“学会了怎么对”。模型在高维参数空间中摸索前进,梯度是它的指南针,loss 是它的方向感
当训练结束时,模型展现出的规则性并不是它“理解”了语言本身,而是我们通过数据和误差函数间接塑造出的行为模式
准备训练数据
模型的目标是从给定的上下文中提取出能回答问题的片段,因此训练数据要覆盖尽可能多样的问题类型和表述方式。
训练数据应明确标注出每个问题对应的答案,以及答案在上下文中的起止位置,确保模型能学习“从哪里找到答案”。
如果模型需要理解语义变换、情感表达等复杂结构,也应在训练集中适当加入此类例子。
SQuAD v2 支持无答案样本(
is_impossible: true),如果任务中允许“不知道”的情况,也应包含此类数据。
训练数据:
{
"version": "v2.0",
"data": [
{
"title": "原神-训练扩展-0",
"paragraphs": [
{
"context": "轻策庄旁的河边,小艾咪正在钓鱼。香菱今天兴高采烈,她成功尝试了新的料理配方。",
"qas": [
{
"id": "原神-训练扩展-0-0",
"question": "谁在钓鱼?",
"answers": [
{
"text": "小艾咪",
"answer_start": 8
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-0-1",
"question": "香菱今天心情如何?",
"answers": [
{
"text": "兴高采烈",
"answer_start": 20
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-0-2",
"question": "香菱尝试了什么?",
"answers": [
{
"text": "新的料理配方",
"answer_start": 31
}
],
"is_impossible": false
}
]
}
]
},
{
"title": "原神-训练扩展-1",
"paragraphs": [
{
"context": "蒙德的酒馆中气氛轻松,温迪正在弹奏新的歌曲。班尼特今天充满活力,他期待下一次冒险。",
"qas": [
{
"id": "原神-训练扩展-1-0",
"question": "谁正在弹奏歌曲?",
"answers": [
{
"text": "温迪",
"answer_start": 11
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-1-1",
"question": "班尼特今天怎么样?",
"answers": [
{
"text": "充满活力",
"answer_start": 27
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-1-2",
"question": "班尼特期待什么?",
"answers": [
{
"text": "下一次冒险",
"answer_start": 35
}
],
"is_impossible": false
}
]
}
]
},
{
"title": "原神-训练扩展-2",
"paragraphs": [
{
"context": "轻策庄旁的河边,小艾咪正在钓鱼。香菱今天兴高采烈,她成功尝试了新的料理配方。",
"qas": [
{
"id": "原神-训练扩展-2-0",
"question": "谁在钓鱼?",
"answers": [
{
"text": "小艾咪",
"answer_start": 8
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-2-1",
"question": "香菱今天心情如何?",
"answers": [
{
"text": "兴高采烈",
"answer_start": 20
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-2-2",
"question": "香菱尝试了什么?",
"answers": [
{
"text": "新的料理配方",
"answer_start": 31
}
],
"is_impossible": false
}
]
}
]
},
{
"title": "原神-训练扩展-3",
"paragraphs": [
{
"context": "璃月港夜晚灯火璀璨,行秋在撰写新的小说章节。重云今天很开心,他吃到了喜欢的冰糕。",
"qas": [
{
"id": "原神-训练扩展-3-0",
"question": "谁今天很开心?",
"answers": [
{
"text": "重云",
"answer_start": 22
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-3-1",
"question": "谁在撰写小说章节?",
"answers": [
{
"text": "行秋",
"answer_start": 10
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-3-2",
"question": "重云吃了什么?",
"answers": [
{
"text": "喜欢的冰糕",
"answer_start": 34
}
],
"is_impossible": false
}
]
}
]
},
{
"title": "原神-训练扩展-4",
"paragraphs": [
{
"context": "璃月港夜晚灯火璀璨,行秋在撰写新的小说章节。重云今天很开心,他吃到了喜欢的冰糕。",
"qas": [
{
"id": "原神-训练扩展-4-0",
"question": "谁今天很开心?",
"answers": [
{
"text": "重云",
"answer_start": 22
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-4-1",
"question": "谁在撰写小说章节?",
"answers": [
{
"text": "行秋",
"answer_start": 10
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-4-2",
"question": "重云吃了什么?",
"answers": [
{
"text": "喜欢的冰糕",
"answer_start": 34
}
],
"is_impossible": false
}
]
}
]
},
{
"title": "原神-训练扩展-5",
"paragraphs": [
{
"context": "稻妻神里屋敷中很安静,神里绫人正在处理家族事务。神里绫华今天特别开心,她刚刚收到旅行者的信。",
"qas": [
{
"id": "原神-训练扩展-5-0",
"question": "谁今天特别开心?",
"answers": [
{
"text": "神里绫华",
"answer_start": 24
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-5-1",
"question": "谁在处理家族事务?",
"answers": [
{
"text": "神里绫人",
"answer_start": 11
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-5-2",
"question": "神里绫华收到什么?",
"answers": [
{
"text": "旅行者的信",
"answer_start": 40
}
],
"is_impossible": false
}
]
}
]
},
{
"title": "原神-训练扩展-6",
"paragraphs": [
{
"context": "清泉镇旁的山丘上,凯亚正在查看地形。菲谢尔今天兴奋不已,她又开始讲述自己的幻想故事。",
"qas": [
{
"id": "原神-训练扩展-6-0",
"question": "谁在查看地形?",
"answers": [
{
"text": "凯亚",
"answer_start": 9
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-6-1",
"question": "菲谢尔今天心情如何?",
"answers": [
{
"text": "兴奋不已",
"answer_start": 23
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-6-2",
"question": "菲谢尔在讲述什么?",
"answers": [
{
"text": "自己的幻想故事",
"answer_start": 34
}
],
"is_impossible": false
}
]
}
]
},
{
"title": "原神-训练扩展-7",
"paragraphs": [
{
"context": "稻妻神里屋敷中很安静,神里绫人正在处理家族事务。神里绫华今天特别开心,她刚刚收到旅行者的信。",
"qas": [
{
"id": "原神-训练扩展-7-0",
"question": "谁今天特别开心?",
"answers": [
{
"text": "神里绫华",
"answer_start": 24
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-7-1",
"question": "谁在处理家族事务?",
"answers": [
{
"text": "神里绫人",
"answer_start": 11
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-7-2",
"question": "神里绫华收到什么?",
"answers": [
{
"text": "旅行者的信",
"answer_start": 40
}
],
"is_impossible": false
}
]
}
]
},
{
"title": "原神-训练扩展-8",
"paragraphs": [
{
"context": "璃月港夜晚灯火璀璨,行秋在撰写新的小说章节。重云今天很开心,他吃到了喜欢的冰糕。",
"qas": [
{
"id": "原神-训练扩展-8-0",
"question": "谁今天很开心?",
"answers": [
{
"text": "重云",
"answer_start": 22
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-8-1",
"question": "谁在撰写小说章节?",
"answers": [
{
"text": "行秋",
"answer_start": 10
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-8-2",
"question": "重云吃了什么?",
"answers": [
{
"text": "喜欢的冰糕",
"answer_start": 34
}
],
"is_impossible": false
}
]
}
]
},
{
"title": "原神-训练扩展-9",
"paragraphs": [
{
"context": "清泉镇旁的山丘上,凯亚正在查看地形。菲谢尔今天兴奋不已,她又开始讲述自己的幻想故事。",
"qas": [
{
"id": "原神-训练扩展-9-0",
"question": "谁在查看地形?",
"answers": [
{
"text": "凯亚",
"answer_start": 9
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-9-1",
"question": "菲谢尔今天心情如何?",
"answers": [
{
"text": "兴奋不已",
"answer_start": 23
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-9-2",
"question": "菲谢尔在讲述什么?",
"answers": [
{
"text": "自己的幻想故事",
"answer_start": 34
}
],
"is_impossible": false
}
]
}
]
},
{
"title": "原神-训练扩展-10",
"paragraphs": [
{
"context": "璃月港夜晚灯火璀璨,行秋在撰写新的小说章节。重云今天很开心,他吃到了喜欢的冰糕。",
"qas": [
{
"id": "原神-训练扩展-10-0",
"question": "谁今天很开心?",
"answers": [
{
"text": "重云",
"answer_start": 22
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-10-1",
"question": "谁在撰写小说章节?",
"answers": [
{
"text": "行秋",
"answer_start": 10
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-10-2",
"question": "重云吃了什么?",
"answers": [
{
"text": "喜欢的冰糕",
"answer_start": 34
}
],
"is_impossible": false
}
]
}
]
},
{
"title": "原神-训练扩展-11",
"paragraphs": [
{
"context": "清泉镇旁的山丘上,凯亚正在查看地形。菲谢尔今天兴奋不已,她又开始讲述自己的幻想故事。",
"qas": [
{
"id": "原神-训练扩展-11-0",
"question": "谁在查看地形?",
"answers": [
{
"text": "凯亚",
"answer_start": 9
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-11-1",
"question": "菲谢尔今天心情如何?",
"answers": [
{
"text": "兴奋不已",
"answer_start": 23
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-11-2",
"question": "菲谢尔在讲述什么?",
"answers": [
{
"text": "自己的幻想故事",
"answer_start": 34
}
],
"is_impossible": false
}
]
}
]
},
{
"title": "原神-训练扩展-12",
"paragraphs": [
{
"context": "清泉镇旁的山丘上,凯亚正在查看地形。菲谢尔今天兴奋不已,她又开始讲述自己的幻想故事。",
"qas": [
{
"id": "原神-训练扩展-12-0",
"question": "谁在查看地形?",
"answers": [
{
"text": "凯亚",
"answer_start": 9
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-12-1",
"question": "菲谢尔今天心情如何?",
"answers": [
{
"text": "兴奋不已",
"answer_start": 23
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-12-2",
"question": "菲谢尔在讲述什么?",
"answers": [
{
"text": "自己的幻想故事",
"answer_start": 34
}
],
"is_impossible": false
}
]
}
]
},
{
"title": "原神-训练扩展-13",
"paragraphs": [
{
"context": "稻妻神里屋敷中很安静,神里绫人正在处理家族事务。神里绫华今天特别开心,她刚刚收到旅行者的信。",
"qas": [
{
"id": "原神-训练扩展-13-0",
"question": "谁今天特别开心?",
"answers": [
{
"text": "神里绫华",
"answer_start": 24
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-13-1",
"question": "谁在处理家族事务?",
"answers": [
{
"text": "神里绫人",
"answer_start": 11
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-13-2",
"question": "神里绫华收到什么?",
"answers": [
{
"text": "旅行者的信",
"answer_start": 40
}
],
"is_impossible": false
}
]
}
]
},
{
"title": "原神-训练扩展-14",
"paragraphs": [
{
"context": "轻策庄旁的河边,小艾咪正在钓鱼。香菱今天兴高采烈,她成功尝试了新的料理配方。",
"qas": [
{
"id": "原神-训练扩展-14-0",
"question": "谁在钓鱼?",
"answers": [
{
"text": "小艾咪",
"answer_start": 8
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-14-1",
"question": "香菱今天心情如何?",
"answers": [
{
"text": "兴高采烈",
"answer_start": 20
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-14-2",
"question": "香菱尝试了什么?",
"answers": [
{
"text": "新的料理配方",
"answer_start": 31
}
],
"is_impossible": false
}
]
}
]
},
{
"title": "原神-训练扩展-15",
"paragraphs": [
{
"context": "稻妻神里屋敷中很安静,神里绫人正在处理家族事务。神里绫华今天特别开心,她刚刚收到旅行者的信。",
"qas": [
{
"id": "原神-训练扩展-15-0",
"question": "谁今天特别开心?",
"answers": [
{
"text": "神里绫华",
"answer_start": 24
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-15-1",
"question": "谁在处理家族事务?",
"answers": [
{
"text": "神里绫人",
"answer_start": 11
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-15-2",
"question": "神里绫华收到什么?",
"answers": [
{
"text": "旅行者的信",
"answer_start": 40
}
],
"is_impossible": false
}
]
}
]
},
{
"title": "原神-训练扩展-16",
"paragraphs": [
{
"context": "蒙德的酒馆中气氛轻松,温迪正在弹奏新的歌曲。班尼特今天充满活力,他期待下一次冒险。",
"qas": [
{
"id": "原神-训练扩展-16-0",
"question": "谁正在弹奏歌曲?",
"answers": [
{
"text": "温迪",
"answer_start": 11
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-16-1",
"question": "班尼特今天怎么样?",
"answers": [
{
"text": "充满活力",
"answer_start": 27
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-16-2",
"question": "班尼特期待什么?",
"answers": [
{
"text": "下一次冒险",
"answer_start": 35
}
],
"is_impossible": false
}
]
}
]
},
{
"title": "原神-训练扩展-17",
"paragraphs": [
{
"context": "轻策庄旁的河边,小艾咪正在钓鱼。香菱今天兴高采烈,她成功尝试了新的料理配方。",
"qas": [
{
"id": "原神-训练扩展-17-0",
"question": "谁在钓鱼?",
"answers": [
{
"text": "小艾咪",
"answer_start": 8
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-17-1",
"question": "香菱今天心情如何?",
"answers": [
{
"text": "兴高采烈",
"answer_start": 20
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-17-2",
"question": "香菱尝试了什么?",
"answers": [
{
"text": "新的料理配方",
"answer_start": 31
}
],
"is_impossible": false
}
]
}
]
},
{
"title": "原神-训练扩展-18",
"paragraphs": [
{
"context": "清泉镇旁的山丘上,凯亚正在查看地形。菲谢尔今天兴奋不已,她又开始讲述自己的幻想故事。",
"qas": [
{
"id": "原神-训练扩展-18-0",
"question": "谁在查看地形?",
"answers": [
{
"text": "凯亚",
"answer_start": 9
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-18-1",
"question": "菲谢尔今天心情如何?",
"answers": [
{
"text": "兴奋不已",
"answer_start": 23
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-18-2",
"question": "菲谢尔在讲述什么?",
"answers": [
{
"text": "自己的幻想故事",
"answer_start": 34
}
],
"is_impossible": false
}
]
}
]
},
{
"title": "原神-训练扩展-19",
"paragraphs": [
{
"context": "蒙德的酒馆中气氛轻松,温迪正在弹奏新的歌曲。班尼特今天充满活力,他期待下一次冒险。",
"qas": [
{
"id": "原神-训练扩展-19-0",
"question": "谁正在弹奏歌曲?",
"answers": [
{
"text": "温迪",
"answer_start": 11
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-19-1",
"question": "班尼特今天怎么样?",
"answers": [
{
"text": "充满活力",
"answer_start": 27
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-19-2",
"question": "班尼特期待什么?",
"answers": [
{
"text": "下一次冒险",
"answer_start": 35
}
],
"is_impossible": false
}
]
}
]
},
{
"title": "原神-训练扩展-20",
"paragraphs": [
{
"context": "璃月港夜晚灯火璀璨,行秋在撰写新的小说章节。重云今天很开心,他吃到了喜欢的冰糕。",
"qas": [
{
"id": "原神-训练扩展-20-0",
"question": "谁今天很开心?",
"answers": [
{
"text": "重云",
"answer_start": 22
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-20-1",
"question": "谁在撰写小说章节?",
"answers": [
{
"text": "行秋",
"answer_start": 10
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-20-2",
"question": "重云吃了什么?",
"answers": [
{
"text": "喜欢的冰糕",
"answer_start": 34
}
],
"is_impossible": false
}
]
}
]
},
{
"title": "原神-训练扩展-21",
"paragraphs": [
{
"context": "稻妻神里屋敷中很安静,神里绫人正在处理家族事务。神里绫华今天特别开心,她刚刚收到旅行者的信。",
"qas": [
{
"id": "原神-训练扩展-21-0",
"question": "谁今天特别开心?",
"answers": [
{
"text": "神里绫华",
"answer_start": 24
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-21-1",
"question": "谁在处理家族事务?",
"answers": [
{
"text": "神里绫人",
"answer_start": 11
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-21-2",
"question": "神里绫华收到什么?",
"answers": [
{
"text": "旅行者的信",
"answer_start": 40
}
],
"is_impossible": false
}
]
}
]
},
{
"title": "原神-训练扩展-22",
"paragraphs": [
{
"context": "清泉镇旁的山丘上,凯亚正在查看地形。菲谢尔今天兴奋不已,她又开始讲述自己的幻想故事。",
"qas": [
{
"id": "原神-训练扩展-22-0",
"question": "谁在查看地形?",
"answers": [
{
"text": "凯亚",
"answer_start": 9
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-22-1",
"question": "菲谢尔今天心情如何?",
"answers": [
{
"text": "兴奋不已",
"answer_start": 23
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-22-2",
"question": "菲谢尔在讲述什么?",
"answers": [
{
"text": "自己的幻想故事",
"answer_start": 34
}
],
"is_impossible": false
}
]
}
]
},
{
"title": "原神-训练扩展-23",
"paragraphs": [
{
"context": "稻妻神里屋敷中很安静,神里绫人正在处理家族事务。神里绫华今天特别开心,她刚刚收到旅行者的信。",
"qas": [
{
"id": "原神-训练扩展-23-0",
"question": "谁今天特别开心?",
"answers": [
{
"text": "神里绫华",
"answer_start": 24
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-23-1",
"question": "谁在处理家族事务?",
"answers": [
{
"text": "神里绫人",
"answer_start": 11
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-23-2",
"question": "神里绫华收到什么?",
"answers": [
{
"text": "旅行者的信",
"answer_start": 40
}
],
"is_impossible": false
}
]
}
]
},
{
"title": "原神-训练扩展-24",
"paragraphs": [
{
"context": "轻策庄旁的河边,小艾咪正在钓鱼。香菱今天兴高采烈,她成功尝试了新的料理配方。",
"qas": [
{
"id": "原神-训练扩展-24-0",
"question": "谁在钓鱼?",
"answers": [
{
"text": "小艾咪",
"answer_start": 8
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-24-1",
"question": "香菱今天心情如何?",
"answers": [
{
"text": "兴高采烈",
"answer_start": 20
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-24-2",
"question": "香菱尝试了什么?",
"answers": [
{
"text": "新的料理配方",
"answer_start": 31
}
],
"is_impossible": false
}
]
}
]
},
{
"title": "原神-训练扩展-25",
"paragraphs": [
{
"context": "蒙德的酒馆中气氛轻松,温迪正在弹奏新的歌曲。班尼特今天充满活力,他期待下一次冒险。",
"qas": [
{
"id": "原神-训练扩展-25-0",
"question": "谁正在弹奏歌曲?",
"answers": [
{
"text": "温迪",
"answer_start": 11
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-25-1",
"question": "班尼特今天怎么样?",
"answers": [
{
"text": "充满活力",
"answer_start": 27
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-25-2",
"question": "班尼特期待什么?",
"answers": [
{
"text": "下一次冒险",
"answer_start": 35
}
],
"is_impossible": false
}
]
}
]
},
{
"title": "原神-训练扩展-26",
"paragraphs": [
{
"context": "蒙德的酒馆中气氛轻松,温迪正在弹奏新的歌曲。班尼特今天充满活力,他期待下一次冒险。",
"qas": [
{
"id": "原神-训练扩展-26-0",
"question": "谁正在弹奏歌曲?",
"answers": [
{
"text": "温迪",
"answer_start": 11
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-26-1",
"question": "班尼特今天怎么样?",
"answers": [
{
"text": "充满活力",
"answer_start": 27
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-26-2",
"question": "班尼特期待什么?",
"answers": [
{
"text": "下一次冒险",
"answer_start": 35
}
],
"is_impossible": false
}
]
}
]
},
{
"title": "原神-训练扩展-27",
"paragraphs": [
{
"context": "璃月港夜晚灯火璀璨,行秋在撰写新的小说章节。重云今天很开心,他吃到了喜欢的冰糕。",
"qas": [
{
"id": "原神-训练扩展-27-0",
"question": "谁今天很开心?",
"answers": [
{
"text": "重云",
"answer_start": 22
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-27-1",
"question": "谁在撰写小说章节?",
"answers": [
{
"text": "行秋",
"answer_start": 10
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-27-2",
"question": "重云吃了什么?",
"answers": [
{
"text": "喜欢的冰糕",
"answer_start": 34
}
],
"is_impossible": false
}
]
}
]
},
{
"title": "原神-训练扩展-28",
"paragraphs": [
{
"context": "轻策庄旁的河边,小艾咪正在钓鱼。香菱今天兴高采烈,她成功尝试了新的料理配方。",
"qas": [
{
"id": "原神-训练扩展-28-0",
"question": "谁在钓鱼?",
"answers": [
{
"text": "小艾咪",
"answer_start": 8
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-28-1",
"question": "香菱今天心情如何?",
"answers": [
{
"text": "兴高采烈",
"answer_start": 20
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-28-2",
"question": "香菱尝试了什么?",
"answers": [
{
"text": "新的料理配方",
"answer_start": 31
}
],
"is_impossible": false
}
]
}
]
},
{
"title": "原神-训练扩展-29",
"paragraphs": [
{
"context": "蒙德的酒馆中气氛轻松,温迪正在弹奏新的歌曲。班尼特今天充满活力,他期待下一次冒险。",
"qas": [
{
"id": "原神-训练扩展-29-0",
"question": "谁正在弹奏歌曲?",
"answers": [
{
"text": "温迪",
"answer_start": 11
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-29-1",
"question": "班尼特今天怎么样?",
"answers": [
{
"text": "充满活力",
"answer_start": 27
}
],
"is_impossible": false
},
{
"id": "原神-训练扩展-29-2",
"question": "班尼特期待什么?",
"answers": [
{
"text": "下一次冒险",
"answer_start": 35
}
],
"is_impossible": false
}
]
}
]
}
]
}验证数据:
验证数据用于在训练过程中周期性评估模型性能,衡量其泛化能力,因此不能和训练数据重复。
验证数据应包含真实任务中可能出现的问题类型,覆盖面不必特别宽,但要具备代表性。
评估指标如 EM(Exact Match)和 F1 分数,都基于验证数据的准确性计算,因此标注必须准确,尤其是
answer_start。如果训练使用了无答案样本,验证集中也应包含部分
is_impossible: true的样本,以评估模型是否能避免瞎猜。
{
"version": "v2.0",
"data": [
{
"title": "原神-验证扩展-0",
"paragraphs": [
{
"context": "蒙德的酒馆中气氛轻松,温迪正在弹奏新的歌曲。班尼特今天充满活力,他期待下一次冒险。",
"qas": [
{
"id": "原神-验证扩展-0-0",
"question": "谁正在弹奏歌曲?",
"answers": [
{
"text": "温迪",
"answer_start": 11
}
],
"is_impossible": false
},
{
"id": "原神-验证扩展-0-1",
"question": "班尼特今天怎么样?",
"answers": [
{
"text": "充满活力",
"answer_start": 27
}
],
"is_impossible": false
},
{
"id": "原神-验证扩展-0-2",
"question": "班尼特期待什么?",
"answers": [
{
"text": "下一次冒险",
"answer_start": 35
}
],
"is_impossible": false
}
]
}
]
},
{
"title": "原神-验证扩展-1",
"paragraphs": [
{
"context": "璃月港夜晚灯火璀璨,行秋在撰写新的小说章节。重云今天很开心,他吃到了喜欢的冰糕。",
"qas": [
{
"id": "原神-验证扩展-1-0",
"question": "谁今天很开心?",
"answers": [
{
"text": "重云",
"answer_start": 22
}
],
"is_impossible": false
},
{
"id": "原神-验证扩展-1-1",
"question": "谁在撰写小说章节?",
"answers": [
{
"text": "行秋",
"answer_start": 10
}
],
"is_impossible": false
},
{
"id": "原神-验证扩展-1-2",
"question": "重云吃了什么?",
"answers": [
{
"text": "喜欢的冰糕",
"answer_start": 34
}
],
"is_impossible": false
}
]
}
]
},
{
"title": "原神-验证扩展-2",
"paragraphs": [
{
"context": "清泉镇旁的山丘上,凯亚正在查看地形。菲谢尔今天兴奋不已,她又开始讲述自己的幻想故事。",
"qas": [
{
"id": "原神-验证扩展-2-0",
"question": "谁在查看地形?",
"answers": [
{
"text": "凯亚",
"answer_start": 9
}
],
"is_impossible": false
},
{
"id": "原神-验证扩展-2-1",
"question": "菲谢尔今天心情如何?",
"answers": [
{
"text": "兴奋不已",
"answer_start": 23
}
],
"is_impossible": false
},
{
"id": "原神-验证扩展-2-2",
"question": "菲谢尔在讲述什么?",
"answers": [
{
"text": "自己的幻想故事",
"answer_start": 34
}
],
"is_impossible": false
}
]
}
]
},
{
"title": "原神-验证扩展-3",
"paragraphs": [
{
"context": "轻策庄旁的河边,小艾咪正在钓鱼。香菱今天兴高采烈,她成功尝试了新的料理配方。",
"qas": [
{
"id": "原神-验证扩展-3-0",
"question": "谁在钓鱼?",
"answers": [
{
"text": "小艾咪",
"answer_start": 8
}
],
"is_impossible": false
},
{
"id": "原神-验证扩展-3-1",
"question": "香菱今天心情如何?",
"answers": [
{
"text": "兴高采烈",
"answer_start": 20
}
],
"is_impossible": false
},
{
"id": "原神-验证扩展-3-2",
"question": "香菱尝试了什么?",
"answers": [
{
"text": "新的料理配方",
"answer_start": 31
}
],
"is_impossible": false
}
]
}
]
},
{
"title": "原神-验证扩展-4",
"paragraphs": [
{
"context": "蒙德的酒馆中气氛轻松,温迪正在弹奏新的歌曲。班尼特今天充满活力,他期待下一次冒险。",
"qas": [
{
"id": "原神-验证扩展-4-0",
"question": "谁正在弹奏歌曲?",
"answers": [
{
"text": "温迪",
"answer_start": 11
}
],
"is_impossible": false
},
{
"id": "原神-验证扩展-4-1",
"question": "班尼特今天怎么样?",
"answers": [
{
"text": "充满活力",
"answer_start": 27
}
],
"is_impossible": false
},
{
"id": "原神-验证扩展-4-2",
"question": "班尼特期待什么?",
"answers": [
{
"text": "下一次冒险",
"answer_start": 35
}
],
"is_impossible": false
}
]
}
]
},
{
"title": "原神-验证扩展-5",
"paragraphs": [
{
"context": "轻策庄旁的河边,小艾咪正在钓鱼。香菱今天兴高采烈,她成功尝试了新的料理配方。",
"qas": [
{
"id": "原神-验证扩展-5-0",
"question": "谁在钓鱼?",
"answers": [
{
"text": "小艾咪",
"answer_start": 8
}
],
"is_impossible": false
},
{
"id": "原神-验证扩展-5-1",
"question": "香菱今天心情如何?",
"answers": [
{
"text": "兴高采烈",
"answer_start": 20
}
],
"is_impossible": false
},
{
"id": "原神-验证扩展-5-2",
"question": "香菱尝试了什么?",
"answers": [
{
"text": "新的料理配方",
"answer_start": 31
}
],
"is_impossible": false
}
]
}
]
},
{
"title": "原神-验证扩展-6",
"paragraphs": [
{
"context": "璃月港夜晚灯火璀璨,行秋在撰写新的小说章节。重云今天很开心,他吃到了喜欢的冰糕。",
"qas": [
{
"id": "原神-验证扩展-6-0",
"question": "谁今天很开心?",
"answers": [
{
"text": "重云",
"answer_start": 22
}
],
"is_impossible": false
},
{
"id": "原神-验证扩展-6-1",
"question": "谁在撰写小说章节?",
"answers": [
{
"text": "行秋",
"answer_start": 10
}
],
"is_impossible": false
},
{
"id": "原神-验证扩展-6-2",
"question": "重云吃了什么?",
"answers": [
{
"text": "喜欢的冰糕",
"answer_start": 34
}
],
"is_impossible": false
}
]
}
]
},
{
"title": "原神-验证扩展-7",
"paragraphs": [
{
"context": "清泉镇旁的山丘上,凯亚正在查看地形。菲谢尔今天兴奋不已,她又开始讲述自己的幻想故事。",
"qas": [
{
"id": "原神-验证扩展-7-0",
"question": "谁在查看地形?",
"answers": [
{
"text": "凯亚",
"answer_start": 9
}
],
"is_impossible": false
},
{
"id": "原神-验证扩展-7-1",
"question": "菲谢尔今天心情如何?",
"answers": [
{
"text": "兴奋不已",
"answer_start": 23
}
],
"is_impossible": false
},
{
"id": "原神-验证扩展-7-2",
"question": "菲谢尔在讲述什么?",
"answers": [
{
"text": "自己的幻想故事",
"answer_start": 34
}
],
"is_impossible": false
}
]
}
]
},
{
"title": "原神-验证扩展-8",
"paragraphs": [
{
"context": "稻妻神里屋敷中很安静,神里绫人正在处理家族事务。神里绫华今天特别开心,她刚刚收到旅行者的信。",
"qas": [
{
"id": "原神-验证扩展-8-0",
"question": "谁今天特别开心?",
"answers": [
{
"text": "神里绫华",
"answer_start": 24
}
],
"is_impossible": false
},
{
"id": "原神-验证扩展-8-1",
"question": "谁在处理家族事务?",
"answers": [
{
"text": "神里绫人",
"answer_start": 11
}
],
"is_impossible": false
},
{
"id": "原神-验证扩展-8-2",
"question": "神里绫华收到什么?",
"answers": [
{
"text": "旅行者的信",
"answer_start": 40
}
],
"is_impossible": false
}
]
}
]
},
{
"title": "原神-验证扩展-9",
"paragraphs": [
{
"context": "稻妻神里屋敷中很安静,神里绫人正在处理家族事务。神里绫华今天特别开心,她刚刚收到旅行者的信。",
"qas": [
{
"id": "原神-验证扩展-9-0",
"question": "谁今天特别开心?",
"answers": [
{
"text": "神里绫华",
"answer_start": 24
}
],
"is_impossible": false
},
{
"id": "原神-验证扩展-9-1",
"question": "谁在处理家族事务?",
"answers": [
{
"text": "神里绫人",
"answer_start": 11
}
],
"is_impossible": false
},
{
"id": "原神-验证扩展-9-2",
"question": "神里绫华收到什么?",
"answers": [
{
"text": "旅行者的信",
"answer_start": 40
}
],
"is_impossible": false
}
]
}
]
}
]
}整理训练数据
以上的数据是标准的SQuAD2.0结构,模型并不支持,需要手动处理一下它们,把上下文、问题、答案展开:
from datasets import load_dataset, DatasetDict, Dataset
def flat(data):
flat_data = []
for d in data:
for paragraph in d["paragraphs"]:
for qa in paragraph["qas"]:
flat_data.append({
"id": qa["id"],
"title": d["title"],
"context": paragraph["context"],
"question": qa["question"],
"answers": qa["answers"],
})
return flat_data
def parse(data):
return DatasetDict({
"train": Dataset.from_list(flat(data["train"]["data"][0])),
"validation": Dataset.from_list(flat(data["validation"]["data"][0])),
})
dataset = parse(load_dataset(
"json",
data_files={
"train": "./training_data/test.json",
"validation": "./training_data/test_validation.json",
},
))
print("# dataset")
print(dataset)
print("# train")
for t in dataset["train"]:
print(t)
print("# validation")
for v in dataset["validation"]:
print(v)展开之后,应该是如下结构:
# dataset
DatasetDict({
train: Dataset({
features: ['id', 'title', 'context', 'question', 'answers'],
num_rows: 4
})
validation: Dataset({
features: ['id', 'title', 'context', 'question', 'answers'],
num_rows: 2
})
})
# train
{'id': 'q1', 'title': '提瓦特冒险', 'context': '提瓦特大陆很大,空正在冒险。刻晴今天心情很好,她想空了。', 'question': '谁今天很高兴?', 'answers': [{'answer_start': 14, 'text': '刻晴'}]}
{'id': 'q2', 'title': '提瓦特冒险', 'context': '提瓦特大陆很大,空正在冒险。刻晴今天心情很好,她想空了。', 'question': '谁在冒险?', 'answers': [{'answer_start': 8, 'text': '空'}]}
{'id': 'q3', 'title': '提瓦特冒险', 'context': '提瓦特大陆很大,空正在冒险。刻晴今天心情很好,她想空了。', 'question': '在哪里冒险?', 'answers': [{'answer_start': 0, 'text': '提瓦特大陆'}]}
{'id': 'q4', 'title': '提瓦特冒险', 'context': '提瓦特大陆很大,空正在冒险。刻晴今天心情很好,她想空了。', 'question': '谁在想空?', 'answers': [{'answer_start': 14, 'text': '刻晴'}]}
# validation
{'id': 'v1', 'title': '提瓦特冒险', 'context': '提瓦特大陆风景优美,空和派蒙一起探索。', 'question': '谁和派蒙一起探索?', 'answers': [{'answer_start': 10, 'text': '空'}]}
{'id': 'v2', 'title': '提瓦特冒险', 'context': '提瓦特大陆风景优美,空和派蒙一起探索。', 'question': '提瓦特大陆的风景如何?', 'answers': [{'answer_start': 7, 'text': '优美'}]}预处理训练数据
加载好模型和序列化器
model = AutoModelForQuestionAnswering.from_pretrained("luhua/chinese_pretrain_mrc_roberta_wwm_ext_large", use_safetensors=True)
tokenizer = AutoTokenizer.from_pretrained("luhua/chinese_pretrain_mrc_roberta_wwm_ext_large")这个加载会有警告:
Some weights of the model checkpoint at luhua/chinese_pretrain_mrc_roberta_wwm_ext_large were not used when initializing BertForQuestionAnswering: ['bert.pooler.dense.bias', 'bert.pooler.dense.weight']
- This IS expected if you are initializing BertForQuestionAnswering from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing BertForQuestionAnswering from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
这不是什么问题,它是这个意思:
加载的是基础BERT模型,却用于 QA
它只是结构不完全匹配时的告知性说明,不代表发生了错误
所谓模型训练,其本质就是:给定输入和期望输出,让模型自动学习其中的隐含映射关系
但模型本身并不理解人类语言,它只接收数字化的向量序列
因此,有专门的工具 —— tokenizer —— 将文本转换为模型可以处理的 token ID 序列。这一步,就像程序中的「序列化」,是人类语言和模型之间的桥梁:
print(tokenizer("谁今天很高兴?")){'input_ids': [101, 6443, 791, 1921, 2523, 7770, 1069, 8043, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}对于我要训练的提问模型,它需要的输入以如下方式构建:
tokenized_example = tokenizer(
"谁今天很高兴?",
"提瓦特大陆很大,空正在冒险。刻晴今天心情很好,她想空了。",
)可以通过tokenizer的docode方法查看输入的人类可读形式:
pip install pyxtensionfrom pyxtension.streams import stream
input_token = stream(tokenized_example["input_ids"]) \
.map(tokenizer.decode) \
.join()
print(input_token)[CLS]谁今天很高兴?[SEP]提瓦特大陆很大,空正在冒险。刻晴今天心情很好,她想空了。[SEP]CLS:起始标记,整个句子开始了
SEP:分隔标记,问题和上下文的切分
需要注意!
[CLS] 和 [SEP] 是 BERT 及其变种模型(如 RoBERTa、DistilBERT)特有的标记,在 GPT 或 T5 等模型中不会出现
可以看到,模型的输入是CLS + 问题 + 上下文,所以训练数据中的
定位问题答案
有了模型输入后,接下来就需要告诉模型正确答案在上下文中的哪里
在抽取式问答任务中,答案是上下文中的一个连续子串
也就是说,要准确标注出答案的起始位置和结束位置,供模型学习如何“圈出”这段文字
但是上边那个字符串只是decode后的人类可读形式,实际上提供给模型的输入是这样的:
[101, 6443, 791, 1921, 2523, 7770, 1069, 8043, 102, 2990, 4482, 4294, 1920, 7355, 2523, 1920, 8024, 4958, 3633, 1762, 1088, 7372, 511, 1174, 3252, 791, 1921, 2552, 2658, 2523, 1962, 8024, 1961, 2682, 4958, 749, 511, 102]它是一个 token 的 ID 序列。在这个模型中,每个汉字恰好是一个 token,但这只是特定 tokenizer 的行为,并不具有通用性。你可以发现,刻晴今天心情很好每个汉字恰好是一个 token,于是,看上去就可以很简单的直接在训练数据中标出答案的起始token位置(answer_start)和结束token位置(answer_end),连答案文本(text)都可以不要,这种情况下它只是一个给人看的东西——之前的简单尝试中,就是这么干的
但在实际上的训练里这种方式并不可取。因为不是所有模型都会这样切分token,有些模型会基于中文词组切分token,每个token有几个字符是不能确定的
所以需要更通用的方式完成这件事情,这也是这次的训练数据中,只标记了起始字符位置(answer_start)和答案文本(text)的原因
也因此,需要获取整个输入中每个token的字符边界,这通过在tokenizer中传参return_offsets_mapping完成:
tokenized_example = tokenizer(
"谁今天很高兴?",
"提瓦特大陆很大,空正在冒险。刻晴今天心情很好,她想空了。",
return_offsets_mapping=True,
)
print(tokenized_example["offset_mapping"])[(0, 0), (0, 1), (1, 2), (2, 3), (3, 4), (4, 5), (5, 6), (6, 7), (0, 0), (0, 1), (1, 2), (2, 3), (3, 4), (4, 5), (5, 6), (6, 7), (7, 8), (8, 9), (9, 10), (10, 11), (11, 12), (12, 13), (13, 14), (14, 15), (15, 16), (16, 17), (17, 18), (18, 19), (19, 20), (20, 21), (21, 22), (22, 23), (23, 24), (24, 25), (25, 26), (26, 27), (27, 28), (0, 0)]offset_mapping表示了整个输入中,每个token的起始字符索引和结束字符索引。这个结构和上文的人类可读形式是可以对应上的
可以发现其中存在(0, 0)这样没有任何字符的token,它们不参与注意力计算,实际考虑时需要小心它们占掉的位置
训练数据中的answer_start是答案在上下文中的字符索引起始位置,于是可以获取问题的token数,加上2(CLS/SEP),就是答案在整个输入中的token偏移量
question_tokens = tokenizer.tokenize("谁今天很高兴?")
context_offset = len(question_tokens) + 2注意:offset_mapping 覆盖的是整个模型输入,包括 [CLS] 问题 [SEP] 上下文 [SEP],所以要跳过 context_offset 之前的 token 索引,只看context部分的 token
基于以上逻辑,可以写出如下的从问题+上下文中提取答案的代码:
def prepare_features(examples):
tokenized = tokenizer(
examples["question"],
examples["context"],
truncation="only_second",
padding="max_length",
return_offsets_mapping=True,
)
start_positions = []
end_positions = []
for i, question in enumerate(examples["question"]):
question_tokens = tokenizer.tokenize(question)
context_offset = len(question_tokens) + 2 # [CLS], [SEP]
answer = examples["answers"][i][0]
answer_start = answer["answer_start"]
answer_end = answer_start + len(answer["text"])
offset_mapping = tokenized["offset_mapping"][i]
start_position = None
end_position = None
for j, offset in enumerate(offset_mapping):
if j < context_offset:
continue
if offset[0] <= answer_start < offset[1]:
start_position = j
if offset[0] < answer_end <= offset[1]:
end_position = j
# noinspection PyUnreachableCode
if start_position is None or end_position is None:
raise ValueError(f"Failed to locate answer({answer["text"]}) in context({examples["context"][i]}) with question({question}).")
# noinspection PyUnreachableCode
start_positions.append(start_position)
end_positions.append(end_position)
tokenized["start_positions"] = start_positions
tokenized["end_positions"] = end_positions
return tokenized注意:这里使用了批量处理(examples),一次prepare_features调用中处理多条数据
以上代码中prepare_features的基本思路:
遍历
offset_mapping,索引小于context_offset的token忽略不要(那些是问题和没有字符的token的索引)从上下文部分的每个token中,以索引是否被包含在起始字符索引和结束字符索引之间为条件,判断该token是否为答案的边界,是则记录其索引
包含了
answer_start和answer_end的token分别为答案的起始索引(start_position)和结束索引(end_position)
定义了提取逻辑之后,就可以使用dataset的map方法完成训练数据集的正式处理
这之中有一个注意点,remove_columns参数
它不只是为了节省内存,最主要的,还因为['id', 'title', 'context', 'question', 'answers']这些列并非模型实际训练中需要的结构,如果它们保留到训练阶段,模型会尝试读取它们,然后发现结构无法对应,然后报错
验证答案标注是否正确
为了确保标注后的 start_positions 和 end_positions 能准确对应到答案文本,在处理完数据集之后,需要验证答案是否被正确标记出来
上文中描述了remove_columns参数的作用,但是为了方便现在验证结果,可以把它暂时移除,保留下原始的上下文信息
对比查看标记前后的dataset结构:
tokenized_dataset = dataset.map(prepare_features, batched=True) #, remove_columns=dataset["train"].column_names
# 有一点需要注意,模型需要的开始索引和结束索引是闭区间,python的切片是左闭右开区间,所以需要在右边 + 1,才能看到标记之后的正确结果
train = tokenized_dataset["train"]
print("---训练数据集---")
for i, train in enumerate(train):
print("#", i, train["context"])
print(train["question"])
print(decode(train["input_ids"][train["start_positions"]:train["end_positions"] + 1]))
print()
validation = tokenized_dataset["validation"]
print("---验证数据集---")
for i, validation in enumerate(validation):
print("#", i, validation["context"])
print(validation["question"])
print(decode(validation["input_ids"][validation["start_positions"]:validation["end_positions"] + 1]))如上文所述,这里为map方法启用了批量处理(batched=True)。输出如下:
---训练数据集---
# 0 稻妻城很热闹,八重神子在书屋策划新书。宵宫今天格外开心,她刚放完一场烟花,也想起了旅行者。
谁今天心情很好?
宵宫
# 1 稻妻城很热闹,八重神子在书屋策划新书。宵宫今天格外开心,她刚放完一场烟花,也想起了旅行者。
谁在策划新书?
八重神子
# 2 稻妻城很热闹,八重神子在书屋策划新书。宵宫今天格外开心,她刚放完一场烟花,也想起了旅行者。
宵宫想起了谁?
旅行者
# 3 蒙德的风依旧温柔,琴在骑士团处理事务。安柏今天兴致勃勃,她想着今晚的飞行比赛。
谁今天兴致勃勃?
安柏
# 4 蒙德的风依旧温柔,琴在骑士团处理事务。安柏今天兴致勃勃,她想着今晚的飞行比赛。
谁在处理事务?
琴
# 5 蒙德的风依旧温柔,琴在骑士团处理事务。安柏今天兴致勃勃,她想着今晚的飞行比赛。
安柏在想什么?
今晚的飞行比赛
# 6 璃月港灯火通明,凝光正审阅一份商业契约。胡桃今天显得特别开心,她提到了与钟离的游玩计划。
胡桃今天怎么样?
特别开心
# 7 璃月港灯火通明,凝光正审阅一份商业契约。胡桃今天显得特别开心,她提到了与钟离的游玩计划。
谁在审阅商业契约?
凝光
# 8 璃月港灯火通明,凝光正审阅一份商业契约。胡桃今天显得特别开心,她提到了与钟离的游玩计划。
胡桃和谁有游玩计划?
钟离
# 9 风起云涌的清泉镇,迪卢克在调查某起盗窃案件。芭芭拉今天唱了很多首歌,她希望能让大家心情更好。
谁今天唱了很多歌?
芭芭拉
# 10 风起云涌的清泉镇,迪卢克在调查某起盗窃案件。芭芭拉今天唱了很多首歌,她希望能让大家心情更好。
谁在调查盗窃案件?
迪卢克
# 11 风起云涌的清泉镇,迪卢克在调查某起盗窃案件。芭芭拉今天唱了很多首歌,她希望能让大家心情更好。
芭芭拉希望带来什么?
大家心情更好
# 12 层岩巨渊下方灯火通明,白术在采集中草药。七七今天心情不错,她想起了以前的旅行经历。
谁今天心情不错?
七七
# 13 层岩巨渊下方灯火通明,白术在采集中草药。七七今天心情不错,她想起了以前的旅行经历。
谁在采集中草药?
白术
# 14 层岩巨渊下方灯火通明,白术在采集中草药。七七今天心情不错,她想起了以前的旅行经历。
七七想起了什么?
以前的旅行经历
---验证数据集---
# 0 须弥的街道安静下来,提纳里外出采药。柯莱今天十分开心,她想着提纳里的话语。
谁今天很开心?
柯莱
# 1 须弥的街道安静下来,提纳里外出采药。柯莱今天十分开心,她想着提纳里的话语。
谁外出采药?
提纳里
# 2 须弥的街道安静下来,提纳里外出采药。柯莱今天十分开心,她想着提纳里的话语。
柯莱在想谁的话语?
提纳里
# 3 雪山依旧寒冷,优菈在训练士兵。诺艾尔今天一整天心情很好,她想起了空一起执行任务时的事。
谁在训练士兵?
优菈
# 4 雪山依旧寒冷,优菈在训练士兵。诺艾尔今天一整天心情很好,她想起了空一起执行任务时的事。
谁今天心情很好?
诺艾尔
# 5 雪山依旧寒冷,优菈在训练士兵。诺艾尔今天一整天心情很好,她想起了空一起执行任务时的事。
诺艾尔想起了谁?
空
# 6 踏鞴砂的锻造声此起彼伏,荒泷一斗在帮助村民修理屋顶。久岐忍今天非常放松,她终于有空休息了。
谁在修理屋顶?
荒泷一斗
# 7 踏鞴砂的锻造声此起彼伏,荒泷一斗在帮助村民修理屋顶。久岐忍今天非常放松,她终于有空休息了。
谁今天很放松?
久岐忍
# 8 踏鞴砂的锻造声此起彼伏,荒泷一斗在帮助村民修理屋顶。久岐忍今天非常放松,她终于有空休息了。
久岐忍终于做了什么?
有空休息了
# 9 翘英庄的农田一片繁忙,甘雨正在帮助农民记录收成。申鹤今天安静地坐在湖边,她在想璃月的传说。
谁在记录收成?
甘雨
# 10 翘英庄的农田一片繁忙,甘雨正在帮助农民记录收成。申鹤今天安静地坐在湖边,她在想璃月的传说。
谁今天坐在湖边?
申鹤
# 11 翘英庄的农田一片繁忙,甘雨正在帮助农民记录收成。申鹤今天安静地坐在湖边,她在想璃月的传说。
申鹤在想什么?
璃月的传说训练优劣判断
为什么上一步使用一个tokenized_dataset接收map之后的结果?
模型不是只训练就行,还要验证训练结果是否可泛化,遇到没见过的数据时,是否依然可以很好地提取结果
只把验证数据集传入Trainer是不够的,Trainer只会计算loss值,而这是不够的,它只是模型在验证集上的交叉熵损失,是模型预测的 token 起止位置与数据集中标注的答案的起止位置之间的差异,没有实际语义,不能体现出模型到底是准确地提取出了结果,还是它只提取了相近的部分
因此,还要结合每轮训练之后的结果计算F1和EM值,它们才是更能体现模型训练结果优劣的指标,可以衡量模型泛化能力是否在提升,同时避免过拟合
而F1和EM的计算,需要使用原始数据作为辅助
F1全称F1 Score,预测答案与真实答案的词级重合程度,部分命中也有分
EM全称Exact Match,是否完全准确命中结果,预测 == 标注,不完全匹配就没分
所以需要保留原始的训练集文本进行比对计算
优劣判断指标
Trainer除了有一个eval_dataset参数用来接收验证数据集,还有一个参数,compute_metrics,用来接收F1和EM的计算逻辑,它会在每轮训练结束后调用
compute_metrics会接收一个EvalPrediction参数,其中有两个参数需要重点关注:
predictions,模型在这一轮测试中,针对每个完整上下文的每个token位置,输出的一个「它是答案起点/终点」的倾向值
predictions分为两个部分,它是一个元组,(起始倾向值logits, 结束倾向值logits)
提取predictions中起始和结束的最大值(numpy.argmax(logits)),就是模型认为最可能是正确答案的起始和结束索引
配合原始数据中的offset_mapping,即可在原始数据的context提取出模型认为的答案文本
label_ids,训练数据集中,针对每个问题标识出来的真实答案索引经过数据集map之后,在完整输入上下文之中的token索引起止位置
label_ids同样分为两个部分,也是一个元组,(起始索引数组[答案1开始索引, 答案2开始索引], 结束索引数组[答案1结束索引, 答案2结束索引])
所以遍历两个部分,即可在原始数据的context提取出原始答案文本——但实际上,直接从map时保留的原始数据中获取文本更简单些
F1和EM的计算算法
有了原始答案文本,有了训练结果文本,接下来就是算法:
F1,将答案文本视为一组词的集合,计算预测答案和真实答案之间的重合程度:
Precision:预测词中有多少是对的,准确率
Recall(召回率):真实词中有多少被预测对了
F1 是二者的调和平均:
这是一个真实的计算案例:
预测答案:风景优美空
真实答案:空派蒙预测token: ["风景", "优美", "空"]
真实token: ["空", "派蒙"]
匹配token: ["空"]所以有如下公式:
EM(Exact Match)
EM = 1.0 if 原始 == 预测 else 0.0
当然,这两个东西要手算还是有些麻烦,所以我们有evaluate:
pip install evaluateimport evaluate
metric = evaluate.load("squad_v2")
def compute_metrics(p):
return metric.compute(
predictions=[
{
"id": "question_id_1",
"prediction_text": "模型预测的答案文本",
"no_answer_probability": 0.0,
},
],
references=[
{
"id": "question_id_1",
"answers": {
"text": ["标准答案1", "标准答案2"],
"answer_start": [起始位置1, 起始位置2],
},
},
],
)n_best_size
有时候,模型的F1和EM不是特别理想,我们想知道模型有没有接近正确答案,错误出在模型本身还是 decode
此时,有一个显而易见的思路:
获取最好的前N个start,获取最好的前N个end,排列组合,将start+end作为分数,排序并统计正确答案的情况
但是它其实并不好,可能存在这么多问题:
这种方式把成对出现的start和end拆解,语义丢失
最好的start+最好的end不代表最好的(start, end)——它们可能出自两个答案组合——导致正确答案的start+end并不是最高的start+end
需要计算n*n个数据,性能不优
所以更合理的方案应该这样得出:
不拆分start和end,把它们作为一个整体考虑
分数计算不应直接采用start+end,应该使用start和end的联合概率
start和end只是模型对于某个位置的倾向度
没有归一化,数值范围没有边界
不具备概率语义
所以应该把倾向度归一转化为对数概率(
log_softmax),可以直接相加,得到的结果就是start和end的联合概率
当前,
logP(start, end)通常是一个很小的数,看着很不方便,可以使用exp把它转换成0~1之间的概率值
于是整理得出如下逻辑:
from scipy.special import log_softmax
start_scores: numpy.ndarray = log_softmax(all_start_logits)
end_scores: numpy.ndarray = log_softmax(all_end_logits)
score = numpy.exp(start_scores[i] + end_scores[j])除开直接计算F1和EM的最佳结果,还可以多看一些数据,比如分析一下模型预测出来的结果中前10个的情况,统计一下这些信息:
正确答案在前十中的排名
模型是否把正确答案当作高置信结果
正确答案的得分
正确答案的“置信度”
模型预测出的第一的得分答案
和正确答案对比,得出模型的正确程度
模型预测出的第一的得分
判断模型是“错得自信”还是“对的不确定”
这些数据都是自定义的,所以需要手动写进Tensorboard中:
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter(log_dir="./model/logs")
def write_record(tags: Tuple[str, str, str], data, step):
data_rank = int(data.name) + 1
writer.add_scalar(tags[0], data_rank, step)
writer.add_scalar(tags[1], data["score"], step)
writer.add_text(tags[2], f"Answer: {data['answer']} (Rank: {data_rank})", step)
writer.flush()完整判断逻辑
那么整合上面的分析,就可以得出优劣应该如何判断了
def write_record(tags: Tuple[str, str, str], data, step):
data_rank = int(data.name) + 1
writer.add_scalar(tags[0], data_rank, step)
writer.add_scalar(tags[1], data["score"], step)
writer.add_text(tags[2], f"Answer: {data['answer']} (Rank: {data_rank})", step)
def log_tensorboard_metrics(df: DataFrame, step: int):
grouped = df.groupby("id")
hit_count = 0
for qa_id, group in grouped:
group = group.reset_index(drop=True)
matched = group[group["is_match"]]
if not matched.empty:
hit_count += 1
best_match = matched.iloc[0]
write_record((f"qa_rank/{qa_id}", f"qa_score/{qa_id}", f"qa_debug/{qa_id}"), best_match, step)
else:
writer.add_scalar(f"qa_rank/{qa_id}", 0, step)
writer.add_scalar(f"qa_score/{qa_id}", 0, step)
writer.add_text(f"qa_debug/{qa_id}", "Answer: <> (Rank: 0)", step)
top1 = group.iloc[0]
write_record((f"top1_rank/{qa_id}", f"top1_score/{qa_id}", f"top1_debug/{qa_id}"), top1, step)
writer.add_scalar("qa_topk_recall", hit_count / len(grouped), step)
writer.flush()
def compute_metrics(p, n_best_size=10, max_answer_ratio=0.4):
validation = dataset["validation"]
tokenized_validation = tokenized_dataset["validation"]
all_start_logits, all_end_logits = p.predictions
predictions = []
references = []
n_best_data = []
for i in range(all_start_logits.shape[0]):
offset_mapping = tokenized_validation["offset_mapping"][i]
start_scores: numpy.ndarray = log_softmax(all_start_logits[i])
end_scores: numpy.ndarray = log_softmax(all_end_logits[i])
answer_length = len(start_scores)
candidates = []
for s in range(answer_length):
for e in range(s, min(answer_length, s + int(answer_length * max_answer_ratio))):
candidates.append((s, e, start_scores[s] + end_scores[e]))
top_candidates = sorted(candidates, key=lambda x: x[2], reverse=True)[:n_best_size]
ref_answers = stream(validation["answers"][i]).map(lambda a: a["text"]).to_list()
for start_logit, end_logit, score in top_candidates:
start_char, end_char = offset_mapping[start_logit][0], offset_mapping[end_logit][1]
answer = validation["context"][i][start_char:end_char]
n_best_data.append(
{
"id": validation["id"][i],
"answer": answer,
"score": numpy.exp(score),
"is_match": any(answer == ref for ref in ref_answers),
},
)
df = pandas.DataFrame(n_best_data)
log_tensorboard_metrics(df, trainer.state.global_step)
for i in range(all_start_logits.shape[0]):
start_logit, end_logit = numpy.argmax(all_start_logits[i]), numpy.argmax(all_end_logits[i])
offset_mapping = tokenized_validation["offset_mapping"][i]
start_char, end_char = offset_mapping[start_logit][0], offset_mapping[end_logit][1]
predictions.append({
"id": validation["id"][i],
"prediction_text": validation["context"][i][start_char:end_char],
"no_answer_probability": 0.0,
})
references.append({
"id": validation["id"][i],
"answers": validation["answers"][i],
})
return metric.compute(
predictions=predictions,
references=references,
)开始训练模型
完成了这么多准备,是时候开始最终步骤——模型训练了
不过在这之前,最后一项准备工作——设置训练参数:
model = AutoModelForQuestionAnswering.from_pretrained("luhua/chinese_pretrain_mrc_roberta_wwm_ext_large", use_safetensors=True)
tokenizer = AutoTokenizer.from_pretrained("luhua/chinese_pretrain_mrc_roberta_wwm_ext_large")
training_args = TrainingArguments(
output_dir="./model",
logging_dir="./model/logs",
logging_strategy="epoch",
report_to="tensorboard",
eval_strategy="epoch",
save_strategy="epoch",
save_total_limit=1,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"],
eval_dataset=tokenized_dataset["validation"],
processing_class=tokenizer,
compute_metrics=compute_metrics,
)TrainingArguments和Trainer参数文档可查看官方页面,我现在选择让多数参数使用默认值
整理以上的流程,完整训练代码如下:
from typing import List, Tuple
import evaluate
import numpy
import pandas
from datasets import load_dataset, DatasetDict, Dataset
from pandas import DataFrame
from pyxtension.streams import stream
from scipy.special import log_softmax
from torch.utils.tensorboard import SummaryWriter
from transformers import AutoModelForQuestionAnswering, AutoTokenizer, TrainingArguments, Trainer
def decode(tokens: List[int]) -> str:
return stream(tokens).map(tokenizer.decode).join()
def flat(data):
flat_data = []
for d in data:
for paragraph in d["paragraphs"]:
for qa in paragraph["qas"]:
flat_data.append({
"id": qa["id"],
"title": d["title"],
"context": paragraph["context"],
"question": qa["question"],
"answers": qa["answers"],
})
return flat_data
def parse(data):
return DatasetDict({
"train": Dataset.from_list(flat(data["train"]["data"][0])),
"validation": Dataset.from_list(flat(data["validation"]["data"][0])),
})
def prepare_features(examples):
tokenized = tokenizer(
examples["question"],
examples["context"],
truncation="only_second",
padding="max_length",
return_offsets_mapping=True,
)
start_positions = []
end_positions = []
for i, question in enumerate(examples["question"]):
question_tokens = tokenizer.tokenize(question)
context_offset = len(question_tokens) + 2 # [CLS], [SEP]
answer = examples["answers"][i][0]
answer_start = answer["answer_start"]
answer_end = answer_start + len(answer["text"])
offset_mapping = tokenized["offset_mapping"][i]
start_position = None
end_position = None
for j, offset in enumerate(offset_mapping):
if j < context_offset:
continue
if offset[0] <= answer_start < offset[1]:
start_position = j
if offset[0] < answer_end <= offset[1]:
end_position = j
# noinspection PyUnreachableCode
if start_position is None or end_position is None:
raise ValueError(f"Failed to locate answer({answer["text"]}) in context({examples["context"][i]}) with question({question}).")
# noinspection PyUnreachableCode
start_positions.append(start_position)
end_positions.append(end_position)
tokenized["start_positions"] = start_positions
tokenized["end_positions"] = end_positions
return tokenized
def write_record(tags: Tuple[str, str, str], data, step):
data_rank = int(data.name) + 1
writer.add_scalar(tags[0], data_rank, step)
writer.add_scalar(tags[1], data["score"], step)
writer.add_text(tags[2], f"Answer: {data['answer']} (Rank: {data_rank})", step)
def log_tensorboard_metrics(df: DataFrame, step: int):
grouped = df.groupby("id")
hit_count = 0
for qa_id, group in grouped:
group = group.reset_index(drop=True)
matched = group[group["is_match"]]
if not matched.empty:
hit_count += 1
best_match = matched.iloc[0]
write_record((f"qa_rank/{qa_id}", f"qa_score/{qa_id}", f"qa_debug/{qa_id}"), best_match, step)
else:
writer.add_scalar(f"qa_rank/{qa_id}", 0, step)
writer.add_scalar(f"qa_score/{qa_id}", 0, step)
writer.add_text(f"qa_debug/{qa_id}", "Answer: <> (Rank: 0)", step)
top1 = group.iloc[0]
write_record((f"top1_rank/{qa_id}", f"top1_score/{qa_id}", f"top1_debug/{qa_id}"), top1, step)
writer.add_scalar("qa_topk_recall", hit_count / len(grouped), step)
writer.flush()
def compute_metrics(p, n_best_size=10, max_answer_ratio=0.4):
validation = dataset["validation"]
tokenized_validation = tokenized_dataset["validation"]
all_start_logits, all_end_logits = p.predictions
predictions = []
references = []
n_best_data = []
for i in range(all_start_logits.shape[0]):
offset_mapping = tokenized_validation["offset_mapping"][i]
start_scores: numpy.ndarray = log_softmax(all_start_logits[i])
end_scores: numpy.ndarray = log_softmax(all_end_logits[i])
answer_length = len(start_scores)
candidates = []
for s in range(answer_length):
for e in range(s, min(answer_length, s + int(answer_length * max_answer_ratio))):
candidates.append((s, e, start_scores[s] + end_scores[e]))
top_candidates = sorted(candidates, key=lambda x: x[2], reverse=True)[:n_best_size]
ref_answers = stream(validation["answers"][i]).map(lambda a: a["text"]).to_list()
for start_logit, end_logit, score in top_candidates:
start_char, end_char = offset_mapping[start_logit][0], offset_mapping[end_logit][1]
answer = validation["context"][i][start_char:end_char]
n_best_data.append(
{
"id": validation["id"][i],
"answer": answer,
"score": numpy.exp(score),
"is_match": any(answer == ref for ref in ref_answers),
},
)
df = pandas.DataFrame(n_best_data)
log_tensorboard_metrics(df, trainer.state.global_step)
for i in range(all_start_logits.shape[0]):
start_logit, end_logit = numpy.argmax(all_start_logits[i]), numpy.argmax(all_end_logits[i])
offset_mapping = tokenized_validation["offset_mapping"][i]
start_char, end_char = offset_mapping[start_logit][0], offset_mapping[end_logit][1]
predictions.append({
"id": validation["id"][i],
"prediction_text": validation["context"][i][start_char:end_char],
"no_answer_probability": 0.0,
})
references.append({
"id": validation["id"][i],
"answers": validation["answers"][i],
})
return metric.compute(
predictions=predictions,
references=references,
)
dataset = parse(load_dataset(
"json",
data_files={
"train": "./training_data/data.json",
"validation": "./training_data/data_validation.json",
},
))
model = AutoModelForQuestionAnswering.from_pretrained("luhua/chinese_pretrain_mrc_roberta_wwm_ext_large", use_safetensors=True)
tokenizer = AutoTokenizer.from_pretrained("luhua/chinese_pretrain_mrc_roberta_wwm_ext_large")
tokenized_dataset = dataset.map(prepare_features, batched=True, remove_columns=dataset["train"].column_names)
metric = evaluate.load("squad_v2")
writer = SummaryWriter(log_dir="./model/logs")
training_args = TrainingArguments(
output_dir="./model",
logging_dir="./model/logs",
logging_strategy="epoch",
report_to="tensorboard",
eval_strategy="epoch",
save_strategy="epoch",
save_total_limit=1,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"],
eval_dataset=tokenized_dataset["validation"],
processing_class=tokenizer,
compute_metrics=compute_metrics,
)
trainer.train()
trainer.save_model("./model/trained")
tokenizer.save_pretrained("./model/trained")这里我直接保存了训练结果,因为
trainer和tokenizer是存在于内存中的变量,运行结束时就消失了而训练的结果checkpoint包含大量冗余信息,并不合适从它们加载这两个变量再运行保存逻辑
因此,直接在训练完成时就保存模型,如果不满意再删除就是了
训练过程如下:
Map: 0%| | 0/90 [00:00<?, ? examples/s]Asking to pad to max_length but no maximum length is provided and the model has no predefined maximum length. Default to no padding.
Asking to truncate to max_length but no maximum length is provided and the model has no predefined maximum length. Default to no truncation.
Map: 100%|██████████| 90/90 [00:00<00:00, 5784.45 examples/s]
Map: 100%|██████████| 30/30 [00:00<00:00, 5943.47 examples/s]
33%|███▎ | 12/36 [00:01<00:02, 8.38it/s]{'loss': 0.0406, 'grad_norm': 0.00022488883405458182, 'learning_rate': 3.472222222222222e-05, 'epoch': 1.0}
33%|███▎ | 12/36 [00:02<00:02, 8.38it/s]
100%|██████████| 4/4 [00:00<00:00, 16.87it/s]
{'eval_loss': 1.2338132364675403e-06, 'eval_exact': 100.0, 'eval_f1': 100.0, 'eval_total': 30, 'eval_HasAns_exact': 100.0, 'eval_HasAns_f1': 100.0, 'eval_HasAns_total': 30, 'eval_best_exact': 100.0, 'eval_best_exact_thresh': 0.0, 'eval_best_f1': 100.0, 'eval_best_f1_thresh': 0.0, 'eval_runtime': 0.2586, 'eval_samples_per_second': 115.999, 'eval_steps_per_second': 15.467, 'epoch': 1.0}
67%|██████▋ | 24/36 [00:08<00:02, 5.84it/s]
{'loss': 0.0001, 'grad_norm': 0.005971414037048817, 'learning_rate': 1.8055555555555555e-05, 'epoch': 2.0}
67%|██████▋ | 24/36 [00:08<00:02, 5.84it/s]
100%|██████████| 4/4 [00:00<00:00, 16.98it/s]
{'eval_loss': 7.510173531954933e-07, 'eval_exact': 100.0, 'eval_f1': 100.0, 'eval_total': 30, 'eval_HasAns_exact': 100.0, 'eval_HasAns_f1': 100.0, 'eval_HasAns_total': 30, 'eval_best_exact': 100.0, 'eval_best_exact_thresh': 0.0, 'eval_best_f1': 100.0, 'eval_best_f1_thresh': 0.0, 'eval_runtime': 0.2536, 'eval_samples_per_second': 118.314, 'eval_steps_per_second': 15.775, 'epoch': 2.0}
100%|██████████| 36/36 [00:14<00:00, 5.64it/s]{'loss': 0.0, 'grad_norm': 0.00016080755449365824, 'learning_rate': 1.388888888888889e-06, 'epoch': 3.0}
100%|██████████| 36/36 [00:14<00:00, 5.64it/s]
100%|██████████| 4/4 [00:00<00:00, 16.33it/s]
{'eval_loss': 5.801514362246962e-07, 'eval_exact': 100.0, 'eval_f1': 100.0, 'eval_total': 30, 'eval_HasAns_exact': 100.0, 'eval_HasAns_f1': 100.0, 'eval_HasAns_total': 30, 'eval_best_exact': 100.0, 'eval_best_exact_thresh': 0.0, 'eval_best_f1': 100.0, 'eval_best_f1_thresh': 0.0, 'eval_runtime': 0.2627, 'eval_samples_per_second': 114.191, 'eval_steps_per_second': 15.225, 'epoch': 3.0}
{'train_runtime': 31.1279, 'train_samples_per_second': 8.674, 'train_steps_per_second': 1.157, 'train_loss': 0.01356143038810842, 'epoch': 3.0}
100%|██████████| 36/36 [00:31<00:00, 1.16it/s]三轮训练中,loss快速下降,说明模型的训练效果很不错...于是就可以保留这次训练之后的模型
当然,如果要查看Tensorboard图表,如下操作:
我是WSL环境,所以有些网络上的问题,忽略那些警告即可
(nlp-journey) fallingangel@FallingAngel:~/nlp-journey/05_local_qa$ tensorboard --logdir=./model/logs
TensorFlow installation not found - running with reduced feature set.
W0621 20:24:50.075287 126367258867520 server_ingester.py:187] Failed to communicate with data server at localhost:45953: <_InactiveRpcError of RPC that terminated with:
status = StatusCode.UNAVAILABLE
details = "failed to connect to all addresses; last error: UNKNOWN: ipv4:172.27.80.1:10809: Endpoint is neither UDS or TCP loopback address."
debug_error_string = "UNKNOWN:Error received from peer {grpc_message:"failed to connect to all addresses; last error: UNKNOWN: ipv4:172.27.80.1:10809: Endpoint is neither UDS or TCP loopback address.", grpc_status:14}"
>
Serving TensorBoard on localhost; to expose to the network, use a proxy or pass --bind_all
TensorBoard 2.19.0 at http://localhost:6006/ (Press CTRL+C to quit)浏览器打开链接http://localhost:6006/就行了
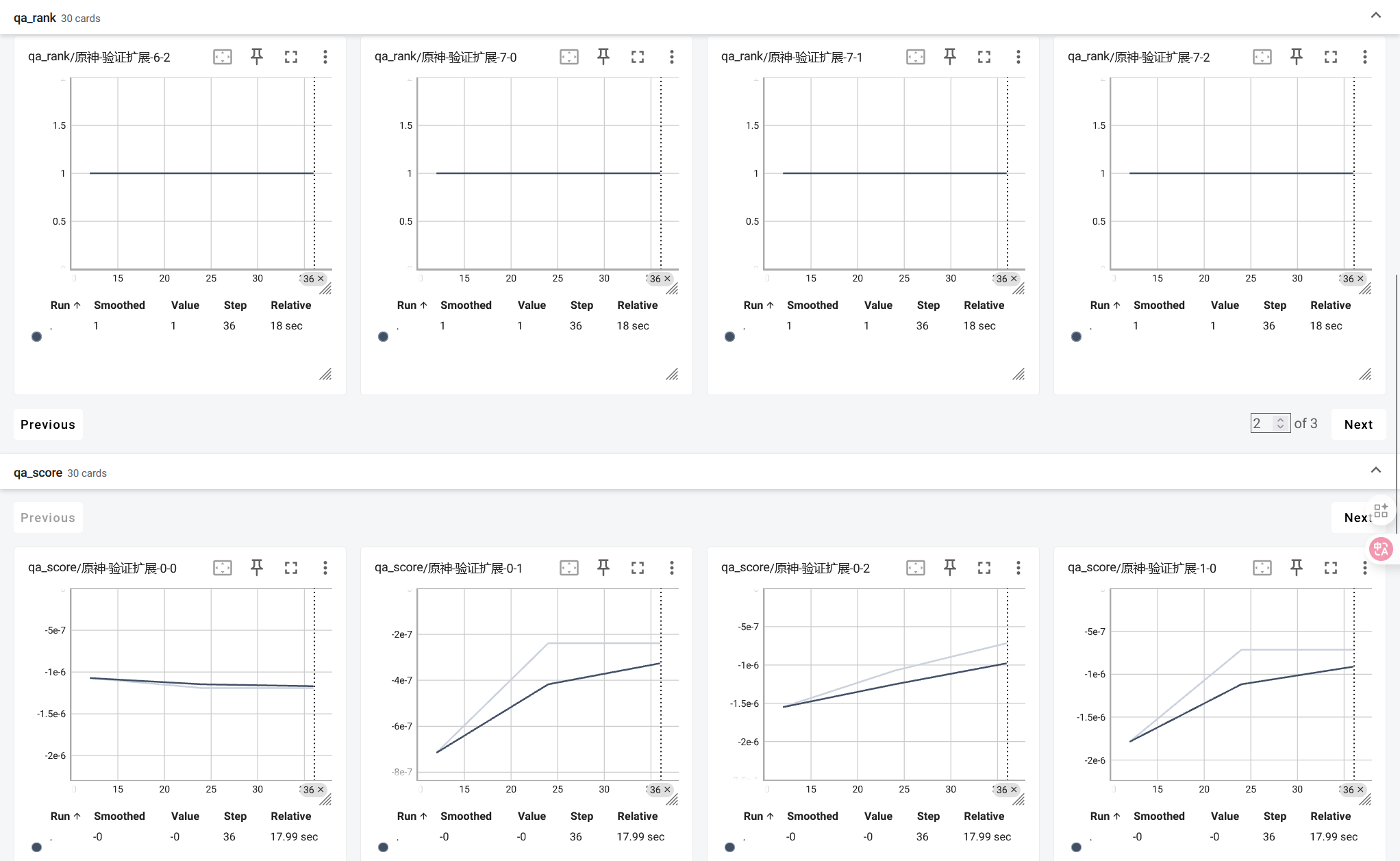
训练结束之后,就和之前那次尝试的步骤几乎一样了:
(nlp-journey) fallingangel@FallingAngel:~/nlp-journey/05_local_qa$ tree model/
model
├── checkpoint-36
│ ├── config.json
│ ├── model.safetensors
│ ├── optimizer.pt
│ ├── rng_state.pth
│ ├── scheduler.pt
│ ├── special_tokens_map.json
│ ├── tokenizer.json
│ ├── tokenizer_config.json
│ ├── trainer_state.json
│ ├── training_args.bin
│ └── vocab.txt
├── logs
│ ├── events.out.tfevents.1750507722.FallingAngel.226427.0
│ └── events.out.tfevents.1750507726.FallingAngel.226427.1
└── trained
├── config.json
├── model.safetensors
├── special_tokens_map.json
├── tokenizer.json
├── tokenizer_config.json
├── training_args.bin
└── vocab.txt
4 directories, 20 files使用新模型:
from transformers import pipeline, AutoModelForQuestionAnswering, AutoTokenizer
model = AutoModelForQuestionAnswering.from_pretrained("./model/trained", use_safetensors=True)
tokenizer = AutoTokenizer.from_pretrained("./model/trained")
pipe = pipeline("question-answering", model=model, tokenizer=tokenizer)
question = ["谁今天很高兴?", "谁在冒险?", "在哪里冒险?", "谁在想空?"]
answers = pipe(question=question, context="提瓦特大陆很大,空正在冒险。刻晴今天心情很好,她想空了。")
for i, answer in enumerate(answers):
print(question[i])
print(answer, "\n")谁今天很高兴?
{'score': 0.9999997615814209, 'start': 14, 'end': 16, 'answer': '刻晴'}
谁在冒险?
{'score': 1.0, 'start': 8, 'end': 9, 'answer': '空'}
在哪里冒险?
{'score': 0.9999966621398926, 'start': 8, 'end': 9, 'answer': '空'}
谁在想空?
{'score': 0.2921316623687744, 'start': 14, 'end': 16, 'answer': '刻晴'}